

更新日志
v1.10 - BDD 风格脚本、Doubao-Seed-2.1 与 MCP 下线
v1.10 新增 BDD 风格的 Gherkin 脚本执行能力,升级推荐模型到 Doubao-Seed-2.1,并正式下线 MCP server 包,后续推荐通过 Skills 与各平台 CLI 让 AI Agent 驱动 Midscene。
BDD 风格脚本(Gherkin)
- 新增
agent.runGherkinScenario(),可在 JavaScript / TypeScript 中直接运行 Gherkin 场景。 - YAML flow 新增
runGherkinScenario步骤,可把自然语言场景写成Given/When/Then结�构并按步骤执行。 Given/When会映射为aiAct,Then以及跟随它的And/But会映射为aiAssert,让测试用例既保持自然语言可读性,又有稳定的步骤结构。- 当前支持围绕单个
Scenario的 Gherkin 子集,BDD 相关能力仍处于 Beta 阶段。详见:BDD 风格脚本(Gherkin)
新增模型支持
- 推荐并支持
Doubao-Seed-2.1-turbo,在当前私有测评集中具备很快的定位速度和良好的定位效果。 - 豆包 Seed 系列统一使用
MIDSCENE_MODEL_FAMILY="doubao-seed",同时继续兼容旧的doubao-visionfamily。详见:常用模型配置、模型策略
MCP 下线
- Midscene 不再发布 MCP server 包,包括
@midscene/web-bridge-mcp、@midscene/android-mcp、@midscene/ios-mcp、@midscene/harmony-mcp、@midscene/computer-mcp和@midscene/mcp。 - 需要 AI 编程 Agent 操作浏览器、移动设备或桌面应用时,请改用 Skills 与各平台 CLI。
- 如果仍依赖 MCP server,请将 Midscene 固定在
1.9.8。这是最后一个包含 MCP 支持的版本。详见:MCP 集成已下线
v1.9 - 新增模型支持、YAML 自动化与 AndroidWorld Benchmark
v1.9 版本扩展了模型支持,改进了 YAML 自动化,并提升了报告查看、Android 自动化、Web 输入和桌面自动化的稳定性。
AndroidWorld Benchmark
Midscene 新增 AndroidWorld benchmark 报告。使用 v1.9.5 测试时,Midscene 达到 Pass@1 93.10%、Pass@2 95.69%、Pass@3 97.41%。详见:AndroidWorld Benchmark 报告
新增模型支持
- 新增 Kimi 和 Xiaomi MiMo 模型支持。详见:常用模型配置
模型与规划更新
aiAct支持图片提示。MIDSCENE_MODEL_REASONING_ENABLED支持default,适配模型默认思考行为。- Gemini thinking content 与 GPT-5 reasoning 配置处理更完整。
aiAct在缓存失效时会回退到模型规划,并清空对应缓存。- AI 请求错误会包含重试次数信息;模型响应解析失败时会保留原始响应;解析后的 locate 结果会先校验再使用。
- 模型 dump 会暴露更多模型响应元数据,包括 raw choice message,以及 usage 中的响应模型名。
deepLocate的搜索区域会显示在报告上。
Chrome 扩展
- Chrome 扩展 Bridge mode 支持文件上传。
- Bridge mode 文件上传支持 file chooser accept 过滤与 WSL 文件路径。
YAML、CLI 与 MCP
1.9.8是最后一个包含 MCP 支持的 Midscene 版本。后续版本会下线 MCP server 包,改为推荐 Skills 与各平台 CLI。- 各平台 CLI 支持传入 agent behavior init args。
- CLI 的 YAML 脚本新增 HarmonyOS target,HarmonyOS 自动化可以通过与 Web、Android、iOS、Computer 一致的脚本运行器流程执行。详见:YAML 脚本自动化、HarmonyOS API
- YAML Web config 支持自定义 HTTP headers。
- YAML Web config 支持通过
downloadPath指定浏览器下载目录。 - YAML 执行会暴露真实错误,不再只落到静默的 "not executed" 结果。
- YAML 批量执行支持重试失败用例。
- YAML 成功执行后会打印报告路径。
- 显式指定的 YAML report 文件名会被正确保留。
- CLI / MCP / Skill 流程可以通过共享参数暴露
deepLocate/deepThink控制项。 - Assert CLI / MCP 工具会转发自定义失败信息,让断言失败更清晰。
- CLI 会从 CLI 包自身解析
@rstest/core,并延迟加载 Rstest core,让外部启动路径下的 framework 执行更稳定。
报告
recordToReport支持自定��义截图。- Report 导出会让图片路径与导出的截图保持一致。
- Report 新增 JSON tree view,方便查看结构化任务和模型数据。
- 优化 Report 截图、标签、Playground server origin 处理与上下文间距。
Studio 与 Recorder
- 稳定 Studio recorder 描述与预览输入合并行为。
- Studio 会更安全地处理无效的模型环境变量配置。
- Recorder 工作流支持生成 Markdown replay output。
Android 自动化
- 改进 Android action controls 和规划提示,提升原生移动端自动化流程的稳定性。
Computer 自动化
- Computer desktop automation 新增 Intel packaging。
- Libnut 滚动现在每个 tick 会发出完整的一次 wheel delta。
问题修复
- 修复 Web integration 中
longPress时长被限制在 600ms 的问题。 - 修复 Web 输入框在输入过程中重新渲染时可能丢字符的问题。
- 修复部分环境下 HarmonyOS MCP 因
photon/sharpWASM 初始化失败而无法启动的问题。 - 修复 Computer RDP 首帧空白截图问题。
- 自动修复 Computer phased-scroll helper 缺失可执行权限的问题。
- 补充 elevated Windows 应用输入丢失警告。
- 补充 Computer 自动化的 IPv6 RDP host 支持。
文档更新
- 补充 Azure OpenAI-compatible endpoint 配置说明。
v1.8 - Midscene Studio 桌面端与多平台增强
v1.8 版本带来全新的桌面端应用 Midscene Studio,新增长按/清空输入等多项 API,并对模型规划行为、设备集成、报告系统和 MCP 工具集进行了全面升级。
全新桌面端应用 Midscene Studio(Beta)
Midscene Studio 是一个基于 Electron 的桌面应用,把多平台 Playground 整合进一个原生界面,开箱即用。当前处于 Beta 阶段,可从 latest release 页面 选择 midscene-studio-beta-* 资源下载最新版 Studio,欢迎试用并反馈问题:
- 多平台 Playground:Web、Android、iOS、HarmonyOS、Computer 在同一个 Studio 应用中无缝切换
- 设备交互预览:Android / iOS / HarmonyOS 设备预览支持手动鼠标和触控控制;Web 预览支持实时画面流式渲染
下一步:在 Studio 中录制生成可回放的 Midscene 脚本
我们正在 Studio 中打造一条「录制 → 脚本 → 回放」的闭环工作流:直接在 Studio 里对真实设备进行操作录制,自动生成结构化的 Midscene 脚本,并能即时在 Studio 内重新回放、调试、导出。该能力将在后续版本中陆续开放,敬请期待。
YAML 工作流增强
- Android runAdbShell timeout:在 JavaScript API 和 YAML 脚本中都支持
timeout选项。详见:Android API、YAML 脚本自动化
新增交互 API
agent.aiLongPress():对指定元素执行长按操作,适用于触发长按菜单等场景。详见 API 文档agent.aiClearInput():清空指定输入框的内容,适合把清空当作独立一步的场景。详见 API 文档
设备与平台集成
- iOS 连接外部 WDA 会话:iOS 支持连接已有的 WebDriverAgent 会话,方便复用外部 WDA 环境
- iOS 设备实现可覆盖:允许使用自定义 iOSDevice 实现,便于深度扩展或定制
- Computer 远程桌面:Computer MCP / CLI 连接工具支持传入 RDP 连接选项,可直接接管远程 Windows 桌面
agentForComputer命名修正:新增agentForComputer作为主推 API,原有agentFromComputer保留��为向后兼容别名- Puppeteer CLI viewport 选项:Puppeteer CLI 新增窗口尺寸配置,方便在命令行中指定运行时的浏览器视口
模型与规划行为
- 使用意图与配置槽位分离:模型使用意图与实际解析到的配置槽位分离,多模型 Planning、定位和报告展示更清晰
- 默认关闭原生思考:对于已支持的模型系列,Midscene 默认关闭模型原生思考,以提升执行速度和稳定性。详见:模型原生的思考模式
- 豆包低延迟模式:支持豆包低延迟模式配置方式,可通过
MIDSCENE_MODEL_EXTRA_BODY_JSON={"service_tier":"fast"}开启。详见:常用模型配置 - GLM-5V-Turbo 支持:新增智谱 GLM-5V-Turbo 模型支持。详见:常用模型配置
- 滚动选择规划优化:优化滚动选择(scrollable select)的规划流程,提升复杂下拉与滚轮选择场景的成功率
MCP 与平台 CLI
- 新增
assertMCP 工具:MCP 新增基于aiAssert的断言工具,AI 助手可以直接调用断言能力。详见:MCP 服务 - Assert 支持图片提示:Assert CLI / MCP 工具支持传入图片作为提示词,便于结合参考图进行断言
- 平台 CLI 接受裸初始化参数:各平台 CLI 简化参数传递方式,直接接受平台 Agent 构造参数
- Playwright fixture 透传 Agent 选项:
PlaywrightAiFixture支持透传PlaywrightAgent构造参数,便于复用 fixture 时自定义 Agent 配置
报告系统
- CLI 合并报告:CLI 新增
report-tool merge子命令,可将多份报告文件合并为一个,便于集中查看 - 报告中记录截图工具调用:截图工具(
take_screenshot)的调用现在会在报告中显示,便于排查截图相关问题
Chrome 扩展
- Chrome Web Store 发布自动化:扩展发布到 Chrome Web Store 的流程已自动化,缩短发布周期
问题修复
- 修复
aiAct在动作真正执行前就触发完成状态的问题 - 修复 Insight prompt 在部分场景下优先使用参考图而不是当前截图的问题
- 修复新标签页导航后的 Bridge 连接问题
- 修复 iOS / HarmonyOS / Computer Playground 点击投影问题
- 修复 HarmonyOS 单次调用
autoDismissKeyboard的配置不生效问题 - 修复 Android Playground 视频流内存占用过高的问题
- 修复 Computer 滚动默认距离与 Web 不一致的问题
- 修复部分模型返回归一化 [0,1000] 坐标超出范围的边界问题
- 修复 Bridge 模式下
aiAct选项未被继承的问题 - 修复 Action API ��返回值与文档不一致的问题
- 修复
maxTokens与意图模型配置不匹配的问题 - 修复服务端端口探测时未使用
0.0.0.0与实际监听 host 不一致的问题 - 修复
aiAct中 deepThink 标记在报告中丢失的问题 - 修复 iOS 输入时偶发的字符丢失问题
- 修复 HarmonyOS system action 延迟覆盖逻辑
v1.7 - 灵活处理报告文件、支持 Qwen 3.6 模型
灵活处理报告文件
从 v1.7.0 开始,你可以把报告文件中的原始截图和 JSON 数据提取出来,或者把报告转录为 Markdown,方便其他工具继续消费这些内容。
示例
你可以把报告文件解析为这样一份 Markdown 文件:
进一步,你可以结合 Remotion Skill 解析这份 Markdown 文件,并生成一个个性化的回放视频。
视频生成结果如下:
Midscene 支持通过命令行工具或者 JavaScript SDK 来解析报告文件,使用方法详见:解析报告文件
新增 Qwen 3.6 模型支持
适配了 Qwen 3.6 模型,可以在 Midscene 中使用最新的通义千问模型。详见:模型配置
Chrome 扩展录制语言设置
Chrome 扩展的录制设置中新增了 YAML 输出语言选项,支持 English、Chinese、Japanese 等多种语言,也可设为 Auto 自动跟随系统语言。
Android / 鸿蒙端改进
- Android 和鸿蒙端新增
terminate操作,支持强制停止指定应用,方便在测试中重置应用状态。详见:Android API、鸿蒙 API - 修复 Android 端在 X/Twitter 上输入时 placeholder 文本被意外保留的问题
- 修复 Android Playground 局域网访问问题
调试体验改进
- 执行日志支持保存到磁盘,便于事后排查问题
- Playground 配置页面保存模型配置时,可运行连通性测试,及时发现配置错误
- Skill CLI 的
run命令支持通过--image参数传入图片作为提示
问题修复
- 修复文件选择器缺失文件时错误提示不清晰的问题
- 修复 CLI 批量运行时错误信息汇总不完整的问题
- 修复 YAML 脚本中
aiScroll缩进格式错误的问题 - 修复
aiLocate元素定位框不准确的问题 - 修复截图失败时缺少降级方案的问题
- 修复部分模型返回空响应时未正确处理的问题
- 修复 CDP 连接模式下标签页复用问题
- 修复
aiQuery在特定数据结构下结果缺失的问题 - 修复 AutoGLM 启动应用时参数格式不正确的问题
- 修复 Playground 中部分下拉菜单显示异常的问题
- 修复模型配置中自定义请求头别名不生效的问题
v1.6 - CDP 连接、双指缩放与多模型增强
v1.6 版本新增了 CDP 浏览器连接模式、跨平台双指缩放手势、GPT-5/GPT-5.4 模型支持,同时对元素定位、报告系统、Chrome 扩展等进行了多项改进。
新增 CDP 浏览器连接模式
支持通过 CDP (Chrome DevTools Protocol) 直接连接已有的浏览器实例进行自动化,无需由 Midscene 启动浏览器,适用于需��要复用已有浏览器会话的场景。详见:Skills - Browser Automation、YAML 脚本运行器 - CDP 连接模式
新增跨平台双指缩放手势
在 Android、iOS、鸿蒙等移动端平台支持 pinch/zoom 双指缩放操作,可用于地图缩放、图片预览等场景。详见:API 文档 - aiPinch
新增 GPT-5 / GPT-5.4 与 Codex app-server provider 支持
适配了 GPT-5 和 GPT-5.4 模型,同时新增 Codex app-server provider,开发者可以使用最新的 OpenAI 模型进行视觉理解与自动化操作。详见:模型配置、模型策略
新增模型请求 extraBody 参数
新增 extraBody 配置,开发者可以在模型 API 请求中传递额外的自定义参数,满足特定模型或部署环境的需求。详见高阶配置中的 MIDSCENE_MODEL_EXTRA_BODY_JSON 环境变量
deepThink 更名为 deepLocate
元素定位相关 API 中的 deepThink 参数正式更名为 deepLocate,更准确地表达其"深度定位"的含义。原有 deepThink 参数仍可使用,但建议逐步迁移。详见:API 文档
Skill CLI 与平台工具增强
- Skill CLI 自定义接口:Skill CLI 支持自定义接口,开发者可以更灵活地扩展 Skill 能力。详见:Skills 文档
- 统一 MCP 工具导出:所有平台包(Web、Android、iOS 等)统一导出 MidsceneTools,在 MCP 场景下集成更简单。详见:MCP 服务
- iOS 终止指定应用:iOS 端支持通过 bundleId 终止指定应用,方便测试流程中重置应用状态。详见:iOS API
- CLI 版本查看:CLI 新增版本查看功能,健康检查中显示各包版本信息,便于排查环境问题
任务取消支持
aiAct 新增 AbortSignal 支持,开发者可以在任务执行过程中随时取消操作,避免长时间等待。详见:API 文档 - aiAct
元素定位优化
优化了 deepLocate 的定位流程,在复杂界面下的定位效率和准确率均有提升。
报告与回放改进
- 大型报告加载更快:报告中的截图支持懒加载,包含大量步骤的报告打开速度显著提升
- 移动端报告更直观:报告回放时展示设备外壳,更直观地还原移动端操作场景
- 时序信息更精确:报告中 AI 调用和操作执行的时序信息精度更高,便于定位性能瓶颈
稳定性改进
- AI 规划偶发解析失败时自动重试一次,减少因网络抖动导致的测试中断
- 设备健康检查新增监控器检测,帮助排查无头环境下的显示问题
Chrome 扩展改进
- 修复录制停止后生成脚本时的崩溃问题
- 修复长时间录制时因消息序列化性能问题导致的卡顿
- Bridge 模式新增启停控制按钮,修复确认操作时连接断开的问题
问题修复
- 修复 MCP 服务在某些情况下变成僵尸进程占用 100% CPU 的问题
- 修复页面跳转过程中截图失败未重试的问题
- 修复 Android 端部分场景下文字输入丢失的问题
- 修复
aiNumber在某些格式下提取结果不正确的问题 - 修复
aiScroll不传参数时的调用异常 - 修复使用 AutoGLM 模型时返回/主页操作在不同平台上的兼容问题
- 修复报告中模型名称包含
/时显示异常的问题 - 修复报告回放结束后播放器未正确重置的问题
- 修复 Playground 中 Deep Think 开关未正确读取环境变量配置的问题
- 修复高分辨率设备截图中光标大小显示不正确的问题
- 修复 Linux 环境下 Chrome 启动路径解析失败的问题
- 修复页面包含 iframe 时元素定位不准确的问题
- 修复鸿蒙端在特定渲染分辨率下屏幕信息解析错误的问题
- 修复 Playground 中取消任务后设备方向显示不正确的问题
v1.5 - HarmonyOS(鸿蒙)自动化支持
v1.5 版本新增了 HarmonyOS 自动化支持,新增 Qwen3.5 和 doubao-seed 2.0 模型支持,同时对桌面自动化、报告系统、Chrome 扩展等进行了多项改进。
新增 HarmonyOS(鸿蒙)自动化支持
新增 @midscene/harmony 包,正式支持 HarmonyOS 平台自动化。Midscene 的自动化能力从 Web、Android、iOS、桌面进一步扩展到鸿蒙生态。
新增 Qwen3.5 与 doubao-seed 2.0 模型支持
适配了通义千问 Qwen3.5 和豆包 doubao-seed 2.0 模型,开发者可以使用更新的模型获得更好的视觉理解效果。
新增通用模型推理配置
新增 MIDSCENE_MODEL_REASONING_EFFORT 环境变量,作为�通用的模型推理强度配置参数,方便开发者在不同模型间统一控制推理行为。
桌面自动化改进
- Xvfb 虚拟显示器支持:在无头 Linux 环境下支持 Xvfb 虚拟显示器,适用于 CI/CD 服务器等无 GUI 环境的桌面自动化
- 连接健康检查:桌面自动化连接时新增健康检查,提升连接可靠性
- macOS 输入优化:macOS 上所有文本输入改用剪贴板方式,避免输入法(IME)导致的输入异常
- 鼠标控制失败检测:自动检测鼠标控制失败并提示管理员权限需求
- 停止执行优化:在停止执行时通过检查 destroyed 状态及时中断截图操作,避免无效等待
截图与显示优化
- 自定义截图缩放:支持自定义截图缩放比例(screenshot shrink),在保证识别准确性的前提下优化性能
- Android 缩放比解耦:将 scalingRatio 从 size() 方法中解耦,提升灵活性
报告系统改进
- 时序信息更详细:报告中的时序信息粒度更细,帮助开发者更精确地分析性能瓶颈
- 合并报告支持目录模式:
mergeReports支持目录模式的报告文件
Chrome 扩展改进
- 新增始终拒绝选项:Chrome 扩展新增"始终拒绝"选项,并修复确认弹窗的竞态条件
- CLI 结束后关闭 Bridge 服务:CLI 命令完成后自动关闭 Bridge 服务器,避免残留进程
问题修复
- 修复表单渲染中 input mode schema 的
z.preprocess处理问题 - 修复 Android 滑动参数传递问题
- 修复 Web 端尺寸计算问题
- 修复
BASE_URL_FIX_SCRIPT闭合标签未被 HTML 解析器识别的问题 - 修复 PlaywrightAgent/PuppeteerAgent 构造函数中 page 为 undefined 的保护处理
v1.4 - Skills:让 AI 助手直接操控你的设备
v1.4 版本推出了 Midscene Skills —— 一套可安装到 Claude Code、OpenClaw 等 AI 助手中的技能包,让 AI 助手直接操控浏览器、桌面、Android 和 iOS 设备。同时本版本还包含独立桌面 MCP 服务、各平台 CLI 独立入口、AI 规划增强等多项改进。
Midscene Skills —— AI 助手的设备操控技能包
Midscene Skills 是一套可安装到 Claude Code、OpenClaw 等 AI 助手中的技能包。安装后,AI 助手可以通过自然语言直接操控浏览器、桌面、Android 和 iOS 设备。
各平台包(@midscene/android、@midscene/ios、@midscene/web 等)现在各自暴露了独立的 CLI 入口,Skills 正是基于此能力构建。
覆盖�平台:
- 浏览器(Puppeteer 无头模式)
- Chrome Bridge(用户自己的桌面 Chrome)
- 桌面(macOS、Windows、Linux)
- Android(通过 ADB)
- iOS(通过 WebDriverAgent)
独立桌面自动化 MCP 包
新增 @midscene/computer-mcp 包,将 PC 桌面自动化能力以独立 MCP 服务的形式提供。开发者可以直接在 Cursor、Trae 等支持 MCP 的工具中使用桌面自动化能力,无需额外集成。
详见文档:PC 桌面自动化
Chrome 扩展支持 MCP 后台连接
Chrome 扩展新增后台 Bridge 模式的 MCP 连接支持,可以将桌面浏览器作为 MCP 工具暴露给 AI 助手,进一步打通 MCP 生态。
AI 规划能力增强
aiAct新增deepLocate选项:在执行操作时启用深度定位,提升复杂界面下的元素定位准确率- Swipe 与 DragAndDrop 语义区分:模型现在能更精确地区分滑动和拖放操作,减少手势规划错误
- LLM 规划增加页面导航限制:防止模型在规划时生成不合理的页面跳转操作,提升任务执行稳定性
- macOS 键盘输入改用 AppleScript:提升桌面自动��化中键盘输入的稳定性和兼容性
- 鼠标移动操作:新增 cursor move 动作支持
YAML 脚本与文件上传增强
- YAML
aiTap支持fileChooserAccept:在 YAML 脚本中可直接处理文件上传对话框 - 支持目录上传:Web 端支持
webkitdirectory类型的文件夹选择上传
Chrome 扩展 Bridge 模式缓存
Bridge 模式下新增缓存支持,复用已有的 AI 规划结果,减少重复调用,提升调试效率。
Android 改进
- 优化文字输入逻辑,提升输入稳定性
iOS 改进
- Playground 实时画面流:iOS Playground 新增实时画面展示,调试时可实时预览设备屏幕。
v1.3 - PC 桌面自动化支持
v1.3 版本带来了全新的 PC 桌面自动化能力,大幅优化了 Android 截图性能,并对报告系统和稳定性进行了多项改进。
全新 PC 桌面自动化支持
Midscene 现在支持 PC 桌面自动化,在 Windows、macOS 和 Linux 上驱动原生键盘和鼠标。无论是 Electron、Qt、WPF 还是原生桌面应用,都可以通过视觉模型方案进行自动化。
核心能力:
- 鼠标操作:单击、双击、右键、移动鼠标、拖放
- 键盘输入:文本输入、组合键(Cmd/Ctrl/Alt/Shift)
- 屏幕截图:捕获任意显示器的截图
- 多显示器支持:同时操作多个显示器
使用方式:
- 支持使用 Computer Playground 零代码试用
- 支持 JavaScript SDK 脚本编写
- 支持 YAML 格式的自动化脚本和命令行工具
- 支持 HTML 报告回放所有操作路径
详见文档:PC 桌面自动化
Android 截图性能大幅提升
开启 Scrcpy 截图模式后,截图耗时从原来的 500–2000ms 降低到 100–200ms,显著提升 Android 自动化的响应速度,特别适用于远程设备调试和高帧率场景。
详见文档:Scrcpy 截图模式
深度思考模式增强
aiAct 的深度思考(deepThink)模式现在不仅用于元素定位,还能优化整体任务规划,在复杂表单、多步骤流程等场景下获得更好的执行效果。
报告体验优化
- 时间线折叠:新增折叠切换按钮,方便查看长任务流程
- 时间单位改为秒:更易读
- 步骤同步高亮:侧边栏步骤高亮与播放器回放实时同步
- 内存占用降低:优化报告生成机制,有效降低运行时内存占用
移动端改进
Android
- 特殊字符和 Unicode 输入更稳定
- Launch 操作时应用包名匹配更宽松(忽略大小写和空格)
- 部分设备截图异常时自动重试
iOS
- Bundle ID 匹配更宽松(忽略大小写和空格)
Web 自动化改进
- 修复 Puppeteer 在非活动标签页截图时可能挂起的问题
- 修复 headed 模式下窗口尺寸不准确的问题
shareBrowserContext模式下支持保留 localStorage 和 sessionStorage- Playwright 多项目配置下,报告中自动区分不同浏览器的测试用例
- 修复 YAML 脚本中 input 操作的
typeOnly模式不生效的问题
其他改进
- 图片处理性能提升
- SVG 图标缓存问题修复
- Playground 模型配置错误现在会显示具体原因
v1.2 - 智谱 AI 开源模型支持与文件上传支持
v1.2 版本中我们加入了对智谱 AI 开源模型的支持,新增了文件上传功能,修复了多个影响使用体验的问题,让自动化测试更加可靠。
新增智谱 AI 开源模型支持
智谱 GLM-V 视觉模型
- 智谱 GLM-V 系列模型是智谱 AI 推出的开源视觉模型,有多种参数的版本,支持云端部署和本地部署。
- 详见:GLM-V 模型配置
智谱 AutoGLM 移动端自动化模型
- 智谱 AutoGLM 是智谱 AI 推出的开源移动端自动化模型,能够根据自然语言指令理解手机屏幕内容,并结合智能规划能力生成操作流程完成用户需求。
- 详见:AutoGLM 模型配置
文件上传功能上线
在 Web 自动化场景中,文件上传是一个常见需求。v1.2 版本为 web 端新增了文件上传能力,支持通过自然语言操作文件输入框,让表单自动化更加完整。
详见:aiTap 文件上传
缓存机制优化
修复了缓存在 DOM 变更后未能及时更新的问题。当页面 DOM 发生变化导致缓存验证失败时,系统现在会自动更新缓存,避免因使用过期缓存而导致的操作失败,提升自动化脚本的稳定性。
报告与 Playground 改进
深度思考标记优化
- 修复了
.aiAct()方法使用深度思考(deepThink)时,报告中未正确显示标记的问题。现在你可以在报告中清晰地看到哪些操作使用了深度思考能力 - 优化了报告中 summary 行的样式,提升整体可读性
Playground 稳定性提升
- 修复了 Playground 在使用 agentFactory 模式时,未在
getActionSpace中正确创建 agent 实例的问题,确保各种使用模式下的正常运行 - 优化了 Playground 输出展示,防止超长的 reportHTML 内容影响界面显示
模型配置更新
针对通义千问(Qwen)模型的深度思考功能,更新了相关配置参数,确保与模型最新版本的兼容性。
v1.1 - aiAct深度思考与可扩展的 MCP SDK
v1.1 版本在模型规划能力与 MCP 扩展性上实现优化,让复杂场景的自动化更稳定,同时为企业级 MCP 服务部署提供更灵活的方案。
aiAct 可开启深度思考能力(deepThink)
在 aiAct 时开启深度思考能力后,模型会更加深入地理解用户意图、优化规划结果,适用于复杂表单、多步骤流程等场景。它会带来更高的准确率,但也会增加规划耗时。
目前已支持阿里云的 Qwen3-vl 与火山引擎的 Doubao-vision 模型,具体请参考 模型策略。
示例用法:
MCP 扩展与 SDK 开放
开发者可以使用 Midscene 暴露的 MCP SDK 灵活部署自己的公共 MCP 服务。此能力适用于任意平台的 Agent 实例。
典型应用场景:
- 在企业内网中运行 MCP 控制私有设备池
- 将 Midscene 能力封装为内部微服务供多团队使用
- 扩展自定义自动化工具链
详见文档:MCP 服务
Chrome 扩展优化
- 修复录制期间的潜在事件丢失问题,提升录制稳定性
- 优化
describeElement的坐标传递,提高元素描述准确性
CLI 与配置增强
- 文件参数支持: 修复 CLI 在同时指定
--config时未正确处理--files参数的问题,现在可灵活组合使用 - 动态配置: 修复 Playground 中环境变量
MIDSCENE_REPLANNING_CYCLE_LIMIT未正确读取的问题
iOS Agent兼容性提升
- 优化
getWindowSize方法,在新版本 API 不可用时自动回退到 legacy endpoint,提升对 WebDriverAgent 版本的兼容性
报告与 Playground 改进
- 修复报告在访问屏幕属性前未正确初始化的问题
- 修复 Playground 中 stop 函数的异常行为
- 优化视频导出时的错误处理,避免 frame cancel 导致的崩溃
感谢贡献者:@FriedRiceNoodles
v1.0 - Midscene v1.0 正式发布!
Midscene v1.0 已发布!欢迎体验,看看它如何帮助你自动化你的工作流程。
查看我们全新的案例展示
在 Web 浏览器中自主注册 Github 表单,通过所有字段校验:
此外还有这些实战案例:
- iOS 自动化 - 美团下单咖啡
- iOS 自动化 - Twitter 自动点赞 @midscene_ai 首条推文
- Android 自动化 - 懂车帝查看小米 SU7 参数
- Android 自动化 - Booking 预订圣诞酒店
- MCP 集成 - Midscene MCP 操作界面发布 prepatch 版本
有社区开发者成功基于 Midscene 与任意界面集成的特性,扩展了机械臂 + 视觉模型 + 语音模型等模块,运用于车机大屏测试场景中,请看下方视频。
🚀 纯视觉路线
从 V1.0 开始,Midscene 全面转向视觉理解方案,提供更稳定可靠的 UI 自动化能力。
视觉模型有以下特点:
- 效果稳定:业界领先的视觉模型(如 Doubao Seed 1.6、Qwen3-VL 等)表现足够稳定,已经可以满足大多数业务需求
- UI 操作规划:视觉模型通常具备较强的 UI 操作规划能��力,能够完成不少复杂的任务流程
- 适用于任意系统:自动化框架不再依赖 UI 渲染的技术栈。无论是 Android、iOS、桌面应用,还是浏览器中的
<canvas>,只要能获取截图,Midscene 即可完成交互操作 - 易于编写:抛弃各类 selector 和 DOM 之后,开发者与模型的“磨合”会变得更简单,不熟悉渲染技术的新人也能很快上手
- token 量显著下降:在去除 DOM 提取之后,视觉方案的 token 使用量可以减少 80%,成本更低,且本地运行速度也变得更快
- 有开源模型解决方案:开源模型表现渐佳,开发者开始有机会进行私有化部署模型,如 Qwen3-VL 提供的 8B、30B 等版本在不少项目中都有着不错的效果
详情请阅读我们更新版的模型策略
🚀 多模型组合,为复杂任务带来更好效果
除了默认的交互场景,Midscene 还定义了 Planning(规划)和 Insight(洞察)两种意图,开发者可以按需为它们启用独立的模型。例如,用 GPT 模型做规划,同时使用默认的 Doubao 模型做元素定位。
多模型组合让开发者可以按需提升复杂需求的处理能力。
🚀 运行时架构优化
针对 Midscene 的运行时表现,我们进行了以下优化:
- 减少对设备信息接口的调用,在确保安全的情况下复用部分上下文信息,提升运行时性能,让大多数的时间消耗集中在模型端
- 优�化 Web 及移动端环境下的 Action Space 组合,向模型开放更合理、更清晰的工具集
🚀 回放报告优化
回放报告是 Midscene 开发者非常依赖的一个特性,它能有效提升脚本的调试效率。 在 v1.0 中,我们更新了回放报告:
- 参数视图:标记出交互参数的位置信息,合并截图信息,快速识别模型的规划结果
- 样式调整:支持以深色模式展示报告,更美观
- Token 消耗的展示:支持按模型汇总 Token 消耗量,分析不同场景的成本情况
🚀 MCP 架构重构
我们重新定义了 Midscene MCP 服务的定位。Midscene MCP 的职责是围绕着视觉驱动的 UI 操作展开,将 iOS / Android / Web 设备 Action Space 中的每个 Action 操作暴露为 MCP 工具,也就是提供各类“原子操作”。
通过这种形式,开发者可以更专注于构建自己的高阶 Agent,而无需关心底层 UI 操作的实现细节,并且时刻获得满意的成功率。
详情请阅读 MCP 文档
🚀 移动端能力增强
iOS 改进
- 新增 WebDriverAgent 5.x-7.x 全版本兼容
- 新增 WebDriver Clear API 支持,解决动态输入框问题
- 提升设备兼容性
Android 改进
- 新增截图轮询回退机制,提升远程设备稳定性
- 新增屏幕方向自动适配(displayId 截图)
- 新增 YAML 脚本
runAdbShell支持
跨平台
- 在 Agent 实例上暴露系统操作接口,包括 Home、Back、RecentApp 等
🚧 API 变更
方法重命名(向后兼容)
- 改名
aiAction()→aiAct()(旧方法保留,有弃用警告) - 改名
logScreenshot()→recordToReport()(旧方法保留,有弃用警告)
环境变量重命名(向后兼容)
- 改名
OPENAI_API_KEY→MIDSCENE_MODEL_API_KEY(新变量优先,旧变量作为备选) - 改名
OPENAI_BASE_URL→MIDSCENE_MODEL_BASE_URL(新变量优先,旧变量作为备选)
⬆️ 升级到最新版
升级项目中的依赖,例如:
npm install @midscene/web@latest --save-dev
npm install @midscene/android@latest --save-dev
npm install @midscene/ios@latest --save-dev
如果使用全局安装的命令行版本:
npm i -g @midscene/cli
V0.30 - 缓存管理升级与移动端体验优化
更灵活的缓存策略
v0.30 版本改进了缓存系统,让你可以根据实际需求控制缓存行为:
- 多种缓存模式可选: 支持只读(read-only)、只写(write-only)、读写(read-write)等策略。例如在 CI 环境中使用只读模式复用缓存,在本地开发时使用只写模式更新缓存
- 自动清理无用缓存: Agent 销毁时可自动清理未使用的缓存记录,避免缓存文件越积越多
- 配置更简洁统一: CLI 和 Agent 的缓存配置参数已统一,无需记忆不同的配置方式
报告管理更便捷
- 支持合并多个报告: 除了 playwright 场景,现在任意场景均支持将多次自动化执行的报告合并为单个文件,方便集中查看和分享测试结果
移动端自动化优化
iOS 平台改进
- 真机支持改进: 移除了 simctl 检查限制,iOS 真机设备的自动化更流畅
- 自动适配设备显示: 实现设备像素比自动检测,确保在不同 iOS 设备上元素定位准确
Android 平台增强
- 灵活的截图优化: 新增
screenshotResizeRatio选项,你可以在保证视觉识别准确性的前提下自定义截图尺寸,减少网络传输和存储开销 - 屏幕信息缓存控制: 通过
alwaysRefreshScreenInfo选项控制是否每次都获取屏幕信息,在稳定环境下可复用缓存提升性能 - 直接执行 ADB 命令: AndroidAgent 新增
runAdbCommand方法,方便执行自定义的设备控制命令
跨平台一致性
- ClearInput 全平台支持: 解决 AI 无法准确规划各平台清空输入的操作问题
功能增强
- 失败分类: CLI 执行结果现在可以区分「跳过的失败」和「真正的失败」,帮助定位问题原因
- aiInput 追加输入: 新增
append选项,在保留现有内容的基础上追加输入,适用于编辑场景 - Chrome 扩展改进:
- 弹窗模式偏好会保存到 localStorage,下次打开记住你的选择
- Bridge 模式支持自动连接,减少手动操作
- 支持 GPT-4o 和非视觉语言模型
类型安全改进
- Zod 模式验证: 为 action 参数引入类型检查,在开发阶段发现参数错误,避免运行时问题
- 数字类型支持: 修复了
aiInput对 number 类型值的支持,类型处理更健壮
问题修复
- 修复了 Playwright 循环依赖导致的潜在问题
- 修复了
aiWaitFor作为首个语句时无法生成报告的问题 - 改进视频录制器延迟逻辑,确保最后的画面帧也能被捕获
- 优化报告展示逻辑,现在可以同时查看错误信息和元素定位信息
- 修复了
aiAction子任务中cacheable选项未正确传递的问题
社区
- Awesome Midscene 板块新增 midscene-java 社区项目
v0.29 - 新增 iOS 平台支持
新增 iOS 平台支持
v0.29 版本最大的亮点是正式引入了对 iOS 平台的支持!现在,你可以通过 WebDriver 连接并自动化 iOS 设备,将 Midscene 的强大 AI 自动化能力扩展到苹果生态系统,了解详情: 支持 iOS 自动化
适配 Qwen3-VL 模型
我们适配了最新的通义千问 Qwen3-VL 模型,开发者可以体验到更快的、更准确的视觉理解能力。详见 模型策略
AI 核心能力增强
- 优化 UI-TARS 模型下的表现:优化 aiAct 规划,改进对话历史管理,提供了更好的上下文感知能力
- 优化 AI 断言与动作:我们更新了
aiAssert的提示词(Prompt)并优化了aiAct的内部实现,使 AI 驱动的断言和动作执行更加精准可靠
报告与调试体验优化
- URL 参数控制回放:为了改善调试体验,现在可以通过 URL 参数直接控制报告回放的默认行为
文档
- 更新了文档部署的缓存策略,确保用户能够及时访问到最新的文档内容
v0.28 - 扩展界面操作能力,构建你自己的 GUI 自动化 Agent(预览特性)
支持与任意界面集成(预览特性)
v0.28 版本推出了与任意界面集成的功能。定义符合 AbstractInterface 定义的界面控制器类,即可获得一个功能齐全的 Midscene Agent。
该功能的典型用途是构建一个针对你自己界面的 GUI 自动化 Agent,比如 IoT 设备、内部应用、车载显示器等!
配合通用 Playground 架构和 SDK 增强功能,开发者能方便地调试自定义设备。
更多请参考 与任意界面集成(预览特性)
Android 平台优化
- 规划缓存支持:为 Android 平台添加了规划缓存功能,提升执行效率
- 输入策略增强:基于 IME 设置优化了输入清除策略,提升 Android 平台的输入体验
- 滚动计算改进:优化了 Android 平台的滚动终点计算算法
手势操作扩展
- 双击操作支持:新增双击动作支持
- 长按与滑动手势:新增长按和滑动手势支持
核心功能增强
- Agent 配置隔离:实现了不同 agent 间的模型配置隔离,避免配置冲突
- 在运行时设置环境变量:为 Agent 新增 useCache 和 replanningCycleLimit 配置选项,提供更精细的控制
- YAML 脚本支持:支持通过 YAML 脚本运行通用的自定义设备,提升自动化能力
问题修复
- 修复了 Qwen 模型的搜索区域大小问题
- 优化了 deepThink 参数处理和矩形尺寸计算
- 解决了 Playwright 双击操作的相关问题
- 改进了 TEXT 动作类型的处理逻辑
文档与社区
- 新增自定义接口文档,帮助开发者更好地扩展功能
- 在 README 中添加了 Awesome Midscene 板块,展示社区项目
v0.27 - 核心模块重构,断言与报告功能全面升级
核心模块重构
在 v0.26 引入 Rslib 提升开发体验、降低贡献门槛的基础上,v0.27 更进一步,对核心模块进行了大规模重构。这使得扩展新设备、添加新 AI 操作的成本变得极低,我们诚挚地欢迎社区开发者踊跃贡献!
由于本次重构涉及面较广,升级后如遇到任何问题,请随时向我们反馈,我们将第一时间跟进处理。
接口优化
aiAssert功能全面增强- 新增
name字段,允许为不同的断言任务命名,方便在 JSON 格式的输出结果中进行识别和解析 - 新增
domIncluded和screenshotIncluded选项,可在断言中灵活控制是否向 AI 发送 DOM 快照和页面截图
- 新增
Chrome 扩展 Playground 升级
- 所有 Agent API 都能在 Playground 上直接调试和运行!交互、提取、验证三大类方法全覆盖,可视化操作和验证,让你的自动化开发效率飙升
报告功能优化
- 新增标记浮层开关:报告播放器增加了隐藏标记浮层的开关,方便用户在回放时查看无遮挡的原始页面视图
问题修复
- 修复了
aiWaitFor在偶现错误导致报告未生成问题 - 降低 Playwright 插件的内存消耗
v0.26 - 工具链全面接入 Rslib,大幅提高开发体验、降低贡献门槛
Web 集成优化
- 支持冻结页面上下文(freezePageContext/unfreezePageContext),使后续所有的操作都复用同一个页面快照,避免多次重复获取页面状态
- 为 Playwright fixture 补全所有 agent api,简化测试脚本编写,解决使用 agentForPage 无法生成报告的问题
Android 自动化增强
- 新增隐藏键盘策略(keyboardDismissStrategy),允许指定自动隐藏键盘的方式
报告功能优化
- 报告内容引入懒解析,解决大体积报告的崩溃问题
- 报告播放器新增自动缩放开关,方便查看全局视角的回放
- 支持 aiAssert / aiQuery 等任务在报告中播放,以完整展示整个页面变动过程
- 修复断言失败时的侧栏状态未显示为失败图标的问题
- 修复报告中下拉筛选器不能切换筛选的问题
构建与工程化
- 构建工具迁移至 Rslib 库开发工具,提升构建效率和开发体验
- 全仓库开启源码跳转,方便开发者查看源码
- MCP npm 包产物体积优化,从 56M 减少到 30M,大幅提高加载速度
问题修复
- CLI 在 keepWindow 为 true 时将自动开启 headed 模式
- 修复 getGlobalConfig 的实现问题,解决环境变量初始化异常问题
- 确保 base64 编码中的 mime-type 正确
- 修复 aiAssert 任务返回值类型
v0.25 - 支持使用图像作为 AI prompt 输入
核心功能增强
- 新增运行环境,支持运行在 Worker 环境
- 支持使用图像作为 AI prompt 输入,详见 使用图片作为提示词
- 图像处理升级,采用 Photon & Sharp 进行高效图片裁剪
Web 集成优化
- 通过坐标获取 XPath,提高缓存可复现性
- 缓存文件将 plan 模块提到最前面,增加可读性
- Chrome Recorder 支持导出所有事件到 markdown 文档
- agent 支持指定 HTML 报告名称,详见 reportFileName
Android 自动化增强
- 长按手势支持
- 下拉刷新支持
问题修复
- 使用全局配置处理环境变量,避免因多打包导致环境无法覆盖的问题
- 当错误对象序列化失败时,手动构造错误信息
- 修复 playwright 报告类型依赖声明顺序问题
- 修复 MCP 打包问题
文档 AI 友好
- LLMs.txt 区分中文与英文,方便 AI 理解
- 每篇文档顶部新增按钮,支持复制为 markdown,方便喂给 AI 使用
其它功能增强
- Chrome Recorder 支持 aiScroll 功能
- 重构 aiAssert 使其与 aiBoolean 实现一致
v0.24 - Android 自动化支持 MCP 调用
Android 自动化支持 MCP 调用
- Android 自动化已全面支持 MCP 调用,为 Android 开发者提供更完善的自动化工具集。详情请参考:MCP 服务
优化输入清空机制
- 针对 Mac 平台的 Puppeteer 增加了双重输入清空机制,保证输入之前清空输入框
开发体验
- 简化本地构建
htmlElement.js的方式,避免循环依赖导致的报告模板构建问题 - 优化了开发工作流,只需要执行
npm run dev即可进入 Midscene 工程开发
v0.23 - 全新报告样式与 YAML 脚本能力增强
报告系统升级
全新报告样式
- 重新设计的测试报告界面,提供更清晰、更美观的测试结果展示
- 优化报告布局和视觉效果,提升用户阅读体�验
- 增强报告的可读性和信息层次结构
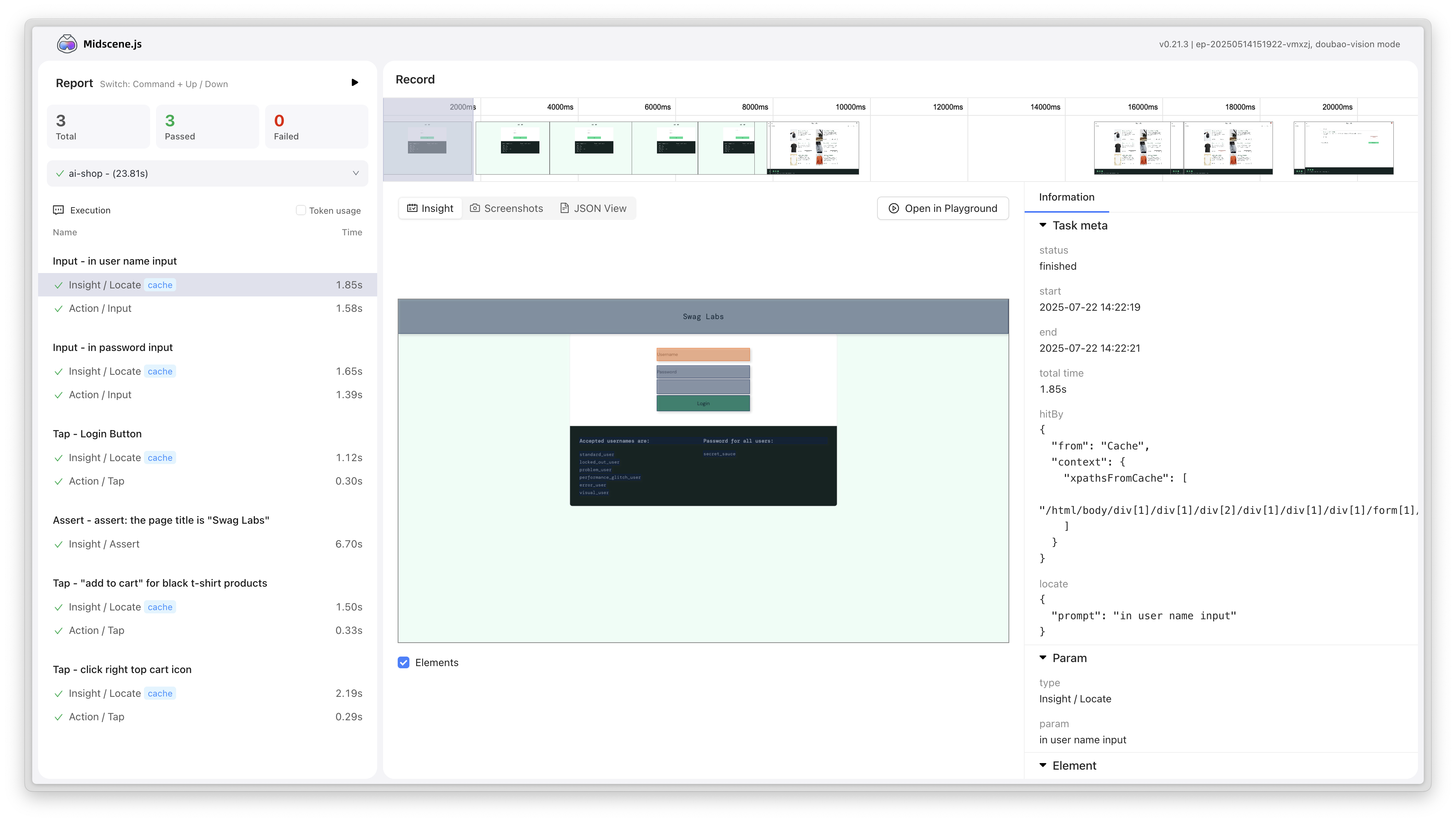
YAML 脚本能力增强
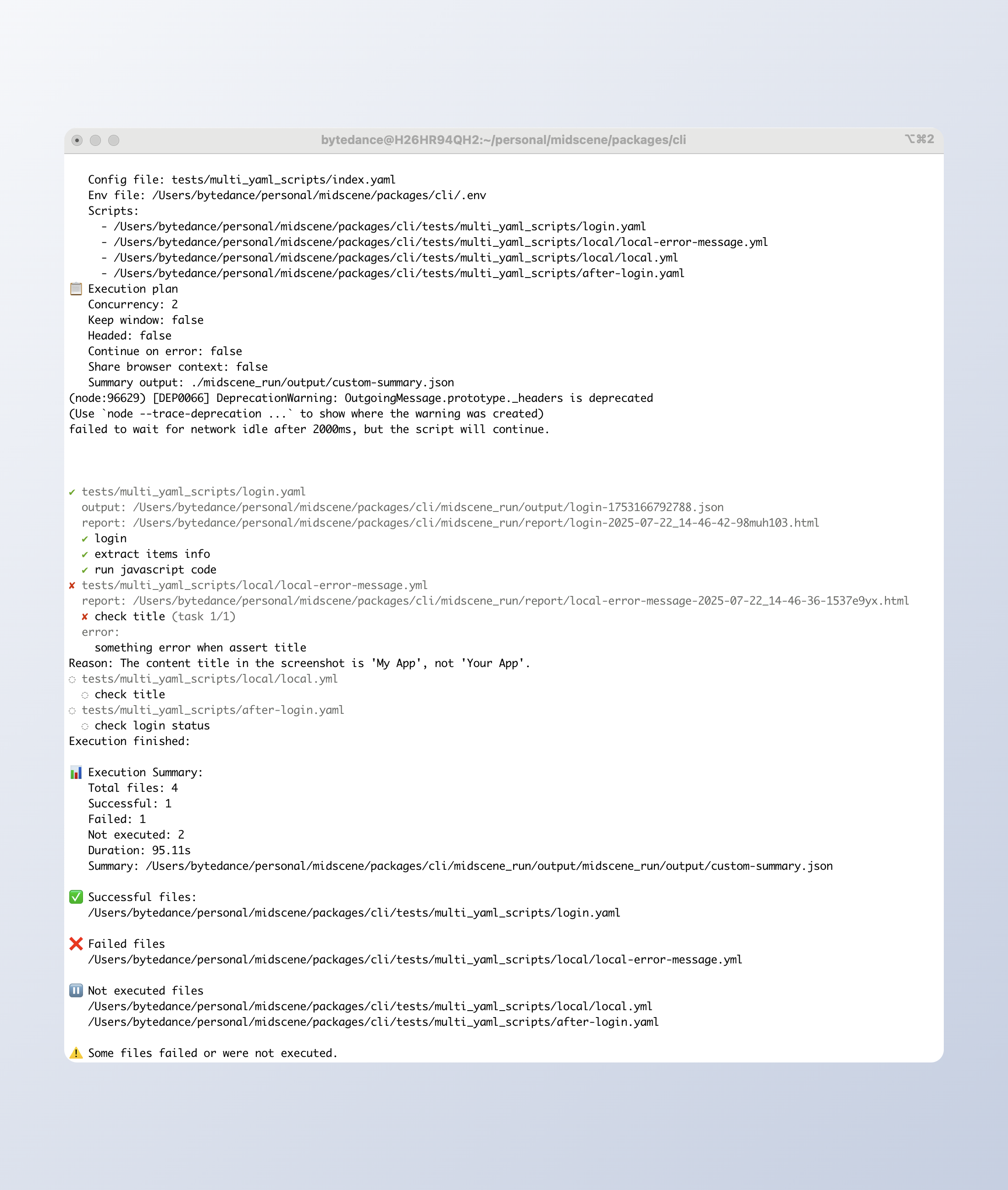
支持多 YAML 文件批量执行
- 新增配置模式,支持配置 YAML 文件运行顺序、浏览器复用策略、并行度
- 支持获取 JSON 格式的运行结果
测试覆盖提升
Android 测试增强
- 新增 Android 平台相关测试用例,提升代码质量和稳定性
- 完善测试覆盖率,确保 Android 功能的可靠性
v0.22 - Chrome 扩展录制功能上线
Web集成增强
全新的录制功能
- Chrome 扩展新增录制功能,可以记录用户在页面上的操作并生成自动化脚本
- 支持录制点击、输入、滚动等常见操作,大大降低自动化脚本编写门槛
- 录制的操作可以直接在 Playground 中回放和调试
存储升级到 IndexedDB
- Chrome 扩展的 Playground 和 Bridge 改为使用 IndexedDB 进行数据存储
- 相比之前的存储方案,提供更大的存储容量和更好的性能
- 支持存储更复杂的数据结构,为未来功能扩展奠定基础
自定义重新规划循环限制
- 设置
MIDSCENE_REPLANNING_CYCLE_LIMIT环境变量,可以自定义在执行操作(aiAct)时允许的最大重新规划循环次数 - 默认值为 10,当 AI 需要重新规划超过这个限制时,会抛出错误建议将任务拆分
- 提供更灵活的任务执行控制,适应不同复杂度的自动化场景
Android 功能增强
截图路径区分
- 为每个截图生成唯一的文件路径,避免文件覆盖问题
- 提升了并发测试场景下的稳定性
v0.21 - Chrome 扩展界面升级
Web集成增强
全新的 Chrome 扩展界面
- 全新的聊天式用户界面设计,提供更好的使用体验
- 界面布局优化,操作更加直观便捷
超时配置灵活性提升
- 支持从测试 fixture 中覆盖超时设置,提供更灵活的超时控制
- 适用场景:不同测试用例需要不同超时时间的场景
统一 Puppeteer 和 Playwright 配置
- 为 Playwright 新增
waitForNavigationTimeout和waitForNetworkIdleTimeout参数 - 统一了 Puppeteer 和 Playwright 的 timeout 选项配置,提供一致的 API 体验,降低学习成本
新增数据导出回调机制
- 新增
agent.onDumpUpdate回调函数,可在数据导出时获得实时通知 - 重构了任务结束后的处理流程,确保异步操作的正确执行
- 适用场景:需要监控或处理导出数据的场景
Android 交互优化
输入体验改进
- 将点击输入改为滑动操作,提升交互响应性和稳定性
- 减少因点击不准确导致的操作失败
v0.20 - 支持传入 XPath 定位元素
Web集成增强
新增 aiAsk 方法
- 可直接向 AI 模型提问,获取当前页面的字符串形式答案
- 适用场景:页面内容问答、信息提取等需要 AI 推理的任务
- 示例:
支持传入 XPath 定位元素
- 定位优先级:指定的 XPath > 缓存 > AI 大模型定位
- 适用场景:已知元素 XPath,需要跳过 AI 大模型定位
- 示例:
Android 改进
Playground 任务可取消
- 支持中断正在执行的自动化任务,提升调试效率
aiLocate API 增强
- 返回设备像素比(Device Pixel Ratio),通常用于计算元素真实坐标
报告生成优化
改进报告生成机制,从批量存储改为单次追加,有效降低内存占用,避免用例数量大时造成的内存溢出
v0.19 - 支持获取完整的执行过程数据
新增 API 获取 Midscene 执行过程数据
为 agent 添加 _unstableLogContent API,即可获取 Midscene 执行过程数据,比如每个步骤的耗时、AI Tokens 消耗情况、页面截图等!
对了,Midscene 的报告就是根据这份数据生成了,也就是说,使用这份数据,你甚至可以定制一个属于你自己的报告!
详情请参考:API 文档
CLI 新增参数支持调整 Midscene 环境变量优先级
默认情况下,dotenv 不会覆盖 .env 文件中同名的全局环境变量。如果希望覆盖,你可以使用 --dotenv-override 选项。
详情请参考:使用 YAML 格式的自动化脚本
大幅减少报告文件大小
裁剪生成的报告中冗余的数据,大幅减少复杂页面的报告文件大小,用户的典型复杂页面报告大小从 47.6M 减小到 15.6M!
v0.18 - 回放报告功能增强
🚀 Midscene 又有更新啦!为你带来高质量的 UI 自动化体验。
在报告中增加自定义节点
- 为 agent 添加
recordToReportAPI,将当前页面的截图作为报告节点。支持设置节点标题和描述,使报告内容更加丰富。适用于关键步骤截图记录、错误状态捕获、UI 验证等。

- 示例:
支持将报告下载为视频
- 支持从报告播放器直接导出视频,点击播放器界面的下载按钮即可保存。
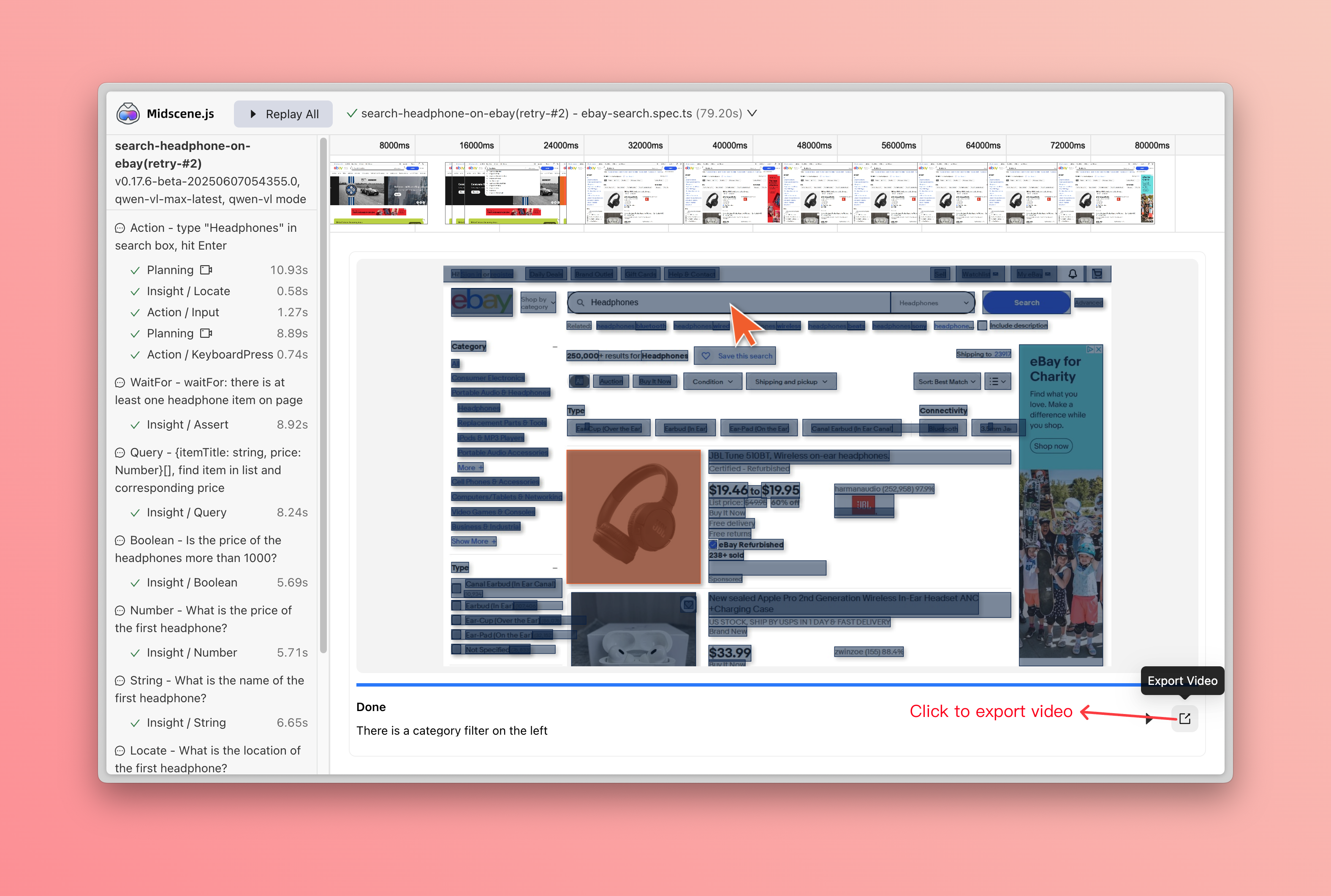
- 适用场景:分享测试结果、存档重现步骤、演示问题复现
Android 暴露更多配置
-
支持使用远程 adb 主机,配置键盘策略
-
autoDismissKeyboard?: boolean- 可选参数,是否在输入文本后自动关闭键盘 -
androidAdbPath?: string- 可选参数,用于指定 adb 可执行文件的路径 -
remoteAdbHost?: string- 可选参数,用于指定远程 adb 主机 -
remoteAdbPort?: number- 可选参数,用于指定远程 adb 端口
-
-
示例:
立即升级版本,体验这些强大新功能!
v0.17 - 让 AI 看见页面 DOM
数据查询 API 全面增强
为满足更多自动化和数据提取场景,以下 API 新增了 options 参数,支持更灵活的 DOM 信息和截图传递:
agent.aiQuery(dataDemand, options)agent.aiBoolean(prompt, options)agent.aiNumber(prompt, options)agent.aiString(prompt, options)
新增 options 参数
domIncluded:是否向模型发送精简后的 DOM 信息,默认值为 false。一般用于提取 UI 中不可见的属性,比如图片的链接。screenshotIncluded:是否向模型发送截图。默认值为 true。
代码示例
新增右键点击能力
你有没有遇到过需要自动化右键操作的场景?现在,Midscene 支持了全新的 agent.aiRightClick() 方法!
功能
使用右键点击页面元素,适用于那些自定义了右键事件的场景。注意:Midscene 无法与浏览器原生菜单交互。
参数说明
locate: 用自然语言描述你要操作的元素options: 可选,支持deepThink(AI精细定位)、cacheable(结果缓存)
示例
示例及其报告
示例页面
示例报告
一个完整示例
在下面的报告文件中,我们展示了一个完整的示例,展示了如何使用新的 aiRightClick API 和新的查询参数来提取包含隐藏属性的联系人数据。
报告文件:puppeteer-2025-06-04_20-41-45-be8ibktz.html
对应代码可以参考我们的示例仓库:puppeteer-demo/extract-data.ts
重构缓存能力
使用 xpath 缓存,而不是基于坐标,提高缓存命中概率。
缓存文件格式使用 yaml 替换 json,提高可读性。
v0.16 - 支持 MCP
Midscene MCP
🤖 使用 Cursor / Trae 帮助编写测试用例。 🕹️ 快速实现浏览器操作,媲美 Manus 平台。 🔧 快速集成 Midscene 能力,融入你的平台和工具。
了解详情: MCP
支持结构化 API
APIs: aiBoolean, aiNumber, aiString, aiLocate
了解详情: 使用结构化 API 优化自动化代码
v0.15 - Android 自动化上线!
Android 自动化上线!
🤖 AI 调试:自然语言调试 📱 支持原生、Lynx 和 WebView 应用 🔁 可回放运行 🛠️ YAML 或 JS SDK ⚡ 自动规划 & 即时操作 API
更多功能
- 支持自定义 midscene_run 目录
- 增强报告文件名生成,支持唯一标识符和分段模式
- 增强超时配置和日志记录,支持网络空闲和导航超时
- 适配 gemini-2.5-pro
了解详情: 支持 Android 自动化
v0.14 - 即时操作 API
即时操作 API
- 新增即时操作 API,增强 AI 操作的准确性
了解详情: 即时操作 API
v0.13 - 深度思考模式
原子 AI 交互方法
- 支持 aiTap, aiInput, aiHover, aiScroll, aiKeyboardPress 等原子操作
深度思考模式
- 增强点击准确性,提供更深层次的上下文理解

v0.12 - 集成 Qwen 2.5 VL
集成 Qwen 2.5 VL 的本地能力
- 保持输出准确性
- 支持更多元素交互
- 成本降低 80% 以上
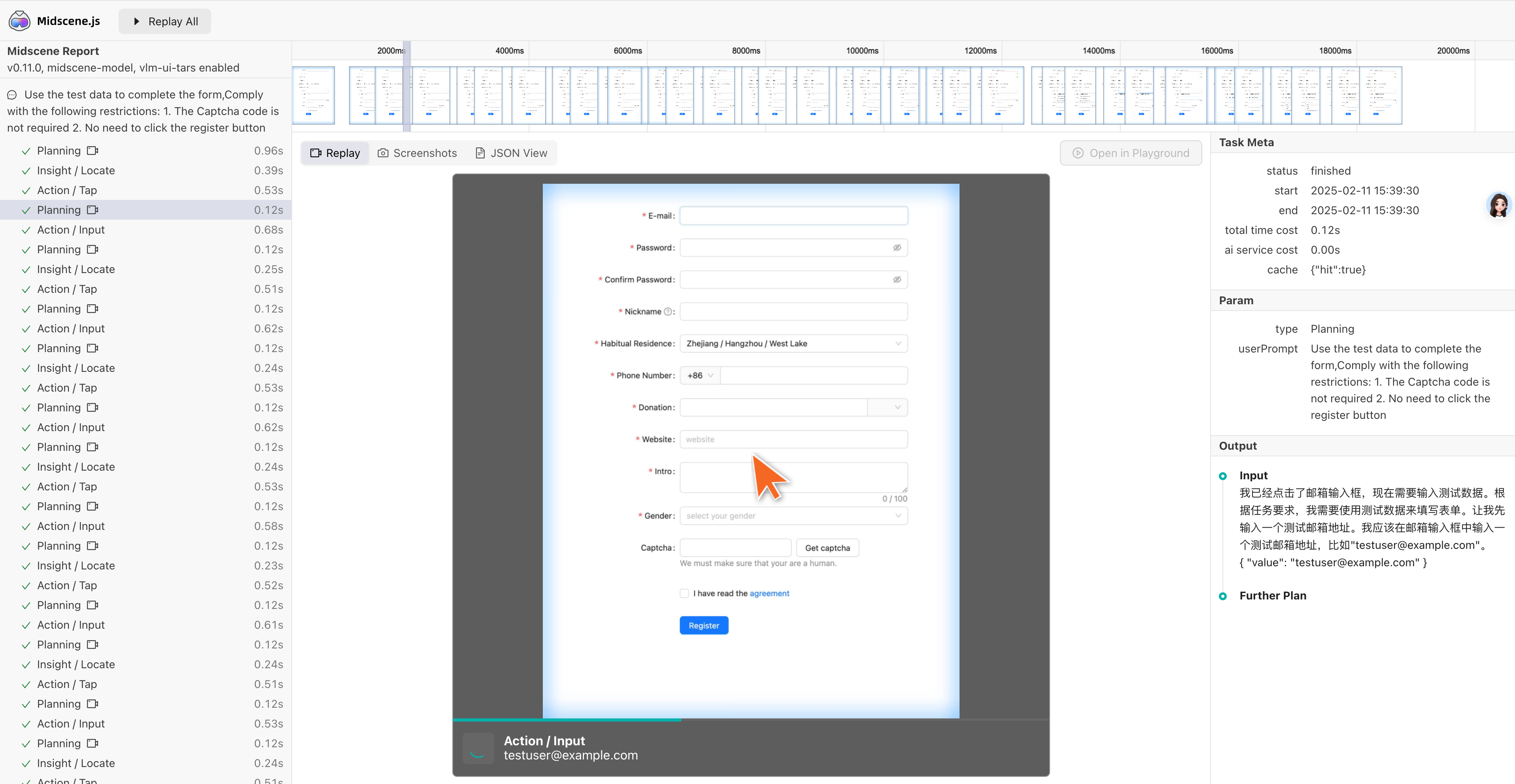
v0.11.0 - UI-TARS 模型缓存
UI-TARS 模型支持缓存
-
通过文档开启缓存 👉: 开启缓存
-
开启效果
优化 DOM 树提取策略
- 优化了 dom 树的信息能力,加速了 GPT 4o 等模型的推理过程
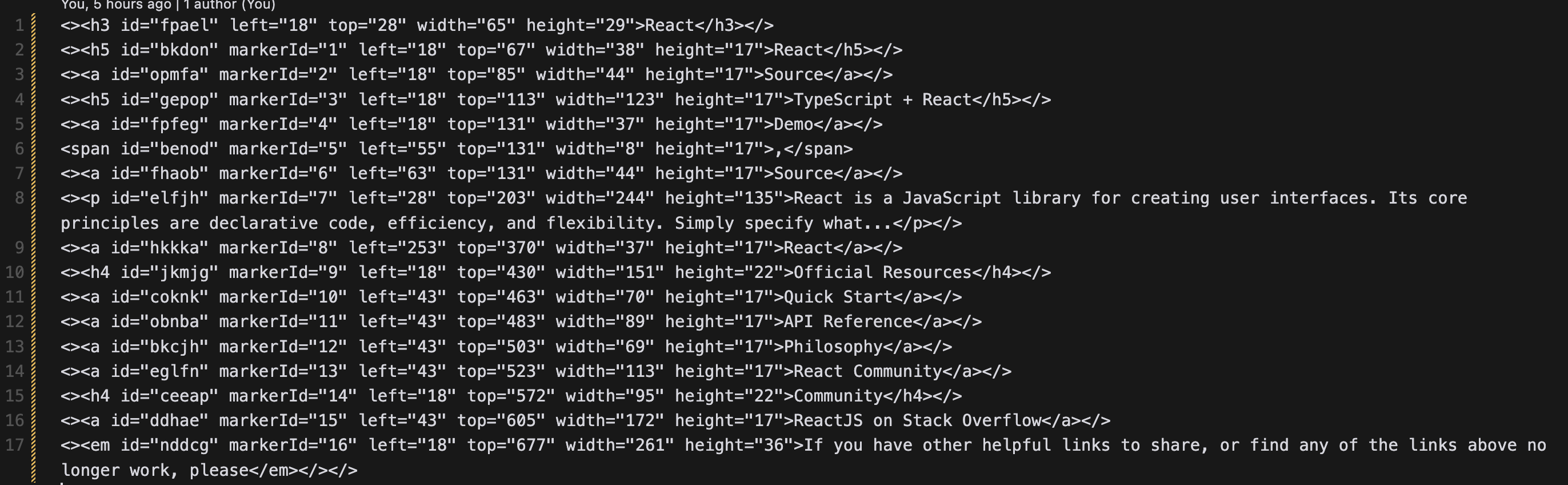
v0.10.0 - UI-TARS 模型上线
UI-TARS 是由 Seed 团队开源的 Native GUI agent 模型。UI-TARS 起名源之星际穿越电影中的 TARS 机器人,它具备高度的智能和自主思考能力。UI-TARS 将图片和人类指令作为输入信息,可以正确的感知下一步的行动,从而逐渐接近人类指令的目标,在 GUI 自动化任务的各项基准测试中均领先于各类开源模型、闭源商业模型。
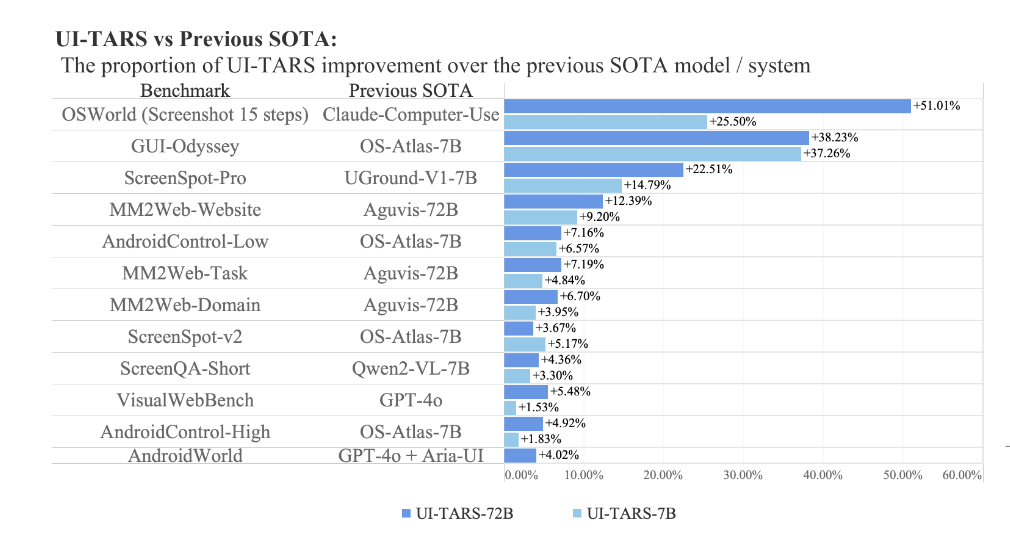
UI-TARS:Pioneering Automated GUI Interaction with Native Agents - Figure 1
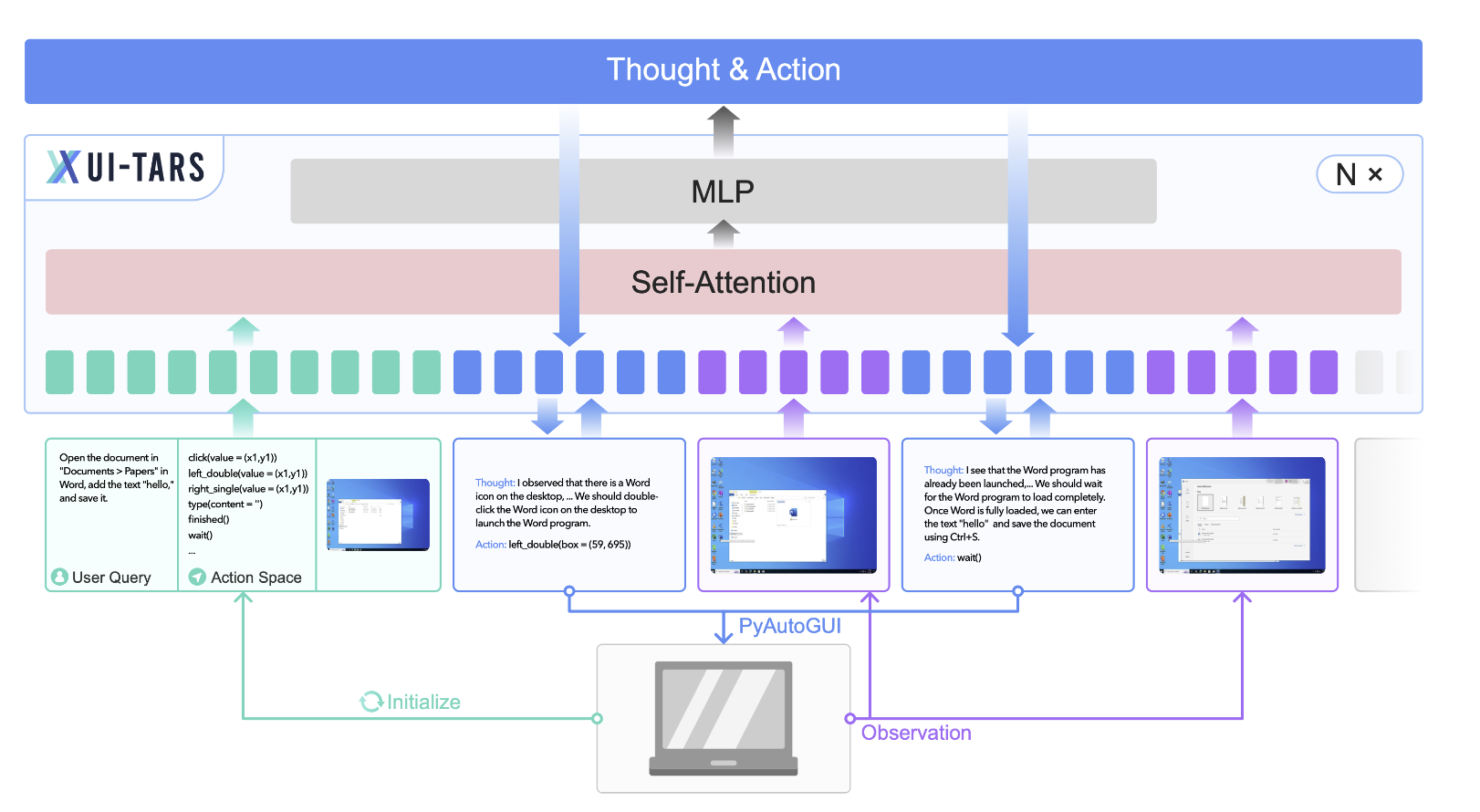
UI-TARS:Pioneering Automated GUI Interaction with Native - Figure 4
模型优势
UI-TARS 模型在 GUI 任务中有以下优势:
-
目标驱动
-
推理速度快
-
Native GUI agent 模型
-
模型开源
-
公司内部私有化部署无数据安全问题
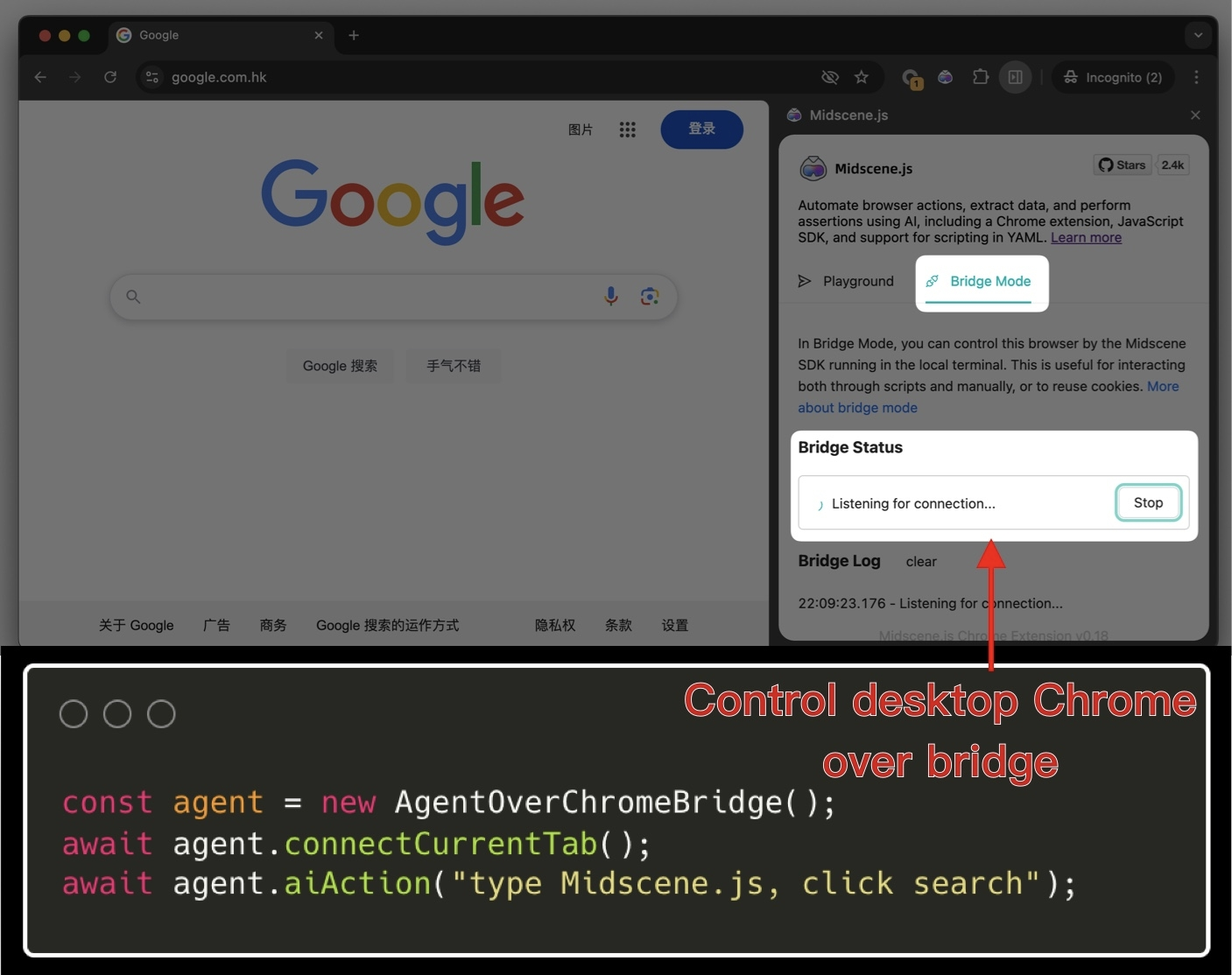
v0.9.0 - 桥接模式上线!
通过 Midscene 浏览器插件,你可以用脚本联动桌面浏览器进行自动化操作了!
我们把它命名为“桥接模式”(Bridge Mode)。
相比于之前各种 CI 环境调试,优势在于:
-
可以复用桌面浏览器,尤其是 Cookie、登录态、前置界面状态等,即刻开启自动化,而不用操心环境搭建
-
支持人工与脚本配合操作界面,提升自动化工具的灵活性
-
简单的业务回归,Bridge Mode 本地跑一下就行
v0.8.0 - Chrome 插件
新增 Chrome 插件,任意页面随时运行 Midscene
通过 Chrome 插件,你可以零代码、任意页面随时运行 Midscene,体验它的 Action \ Query \ Assert 等能力。
体验方式: 使用 Chrome 插件体验 Midscene
v0.7.0 - Playground 能力
新增 Playground 能力,随时发起调试
再也不用频繁重跑脚本调试 Prompt 了!
在全新的测试报告页上,你可以随时对 AI 执行结果进行调试,包括页面操作、页面信息提取、页面断言。
v0.6.0 - 支持字节豆包模型
模型:**支持字节豆包
全新支持调用豆包模型调用,参考下方环境变量即可体验。
总结目前豆包模型的可用性:
-
目前豆包只有纯文本模型,也就是“看”不到图片。在纯粹通过界面文本进行推理的场景中表现尚可。
-
如果用例需要结合分析界面 UI,它完全不可用
举例:
✅ 多肉葡萄的价格 (可以通过界面文字的顺序猜出来)
✅ 切换语言文本按钮(可以是:中文,英文文本) (可以通过界面文字内容猜出来)
❌ 左下角播放按钮 (需要图像理解,失败)
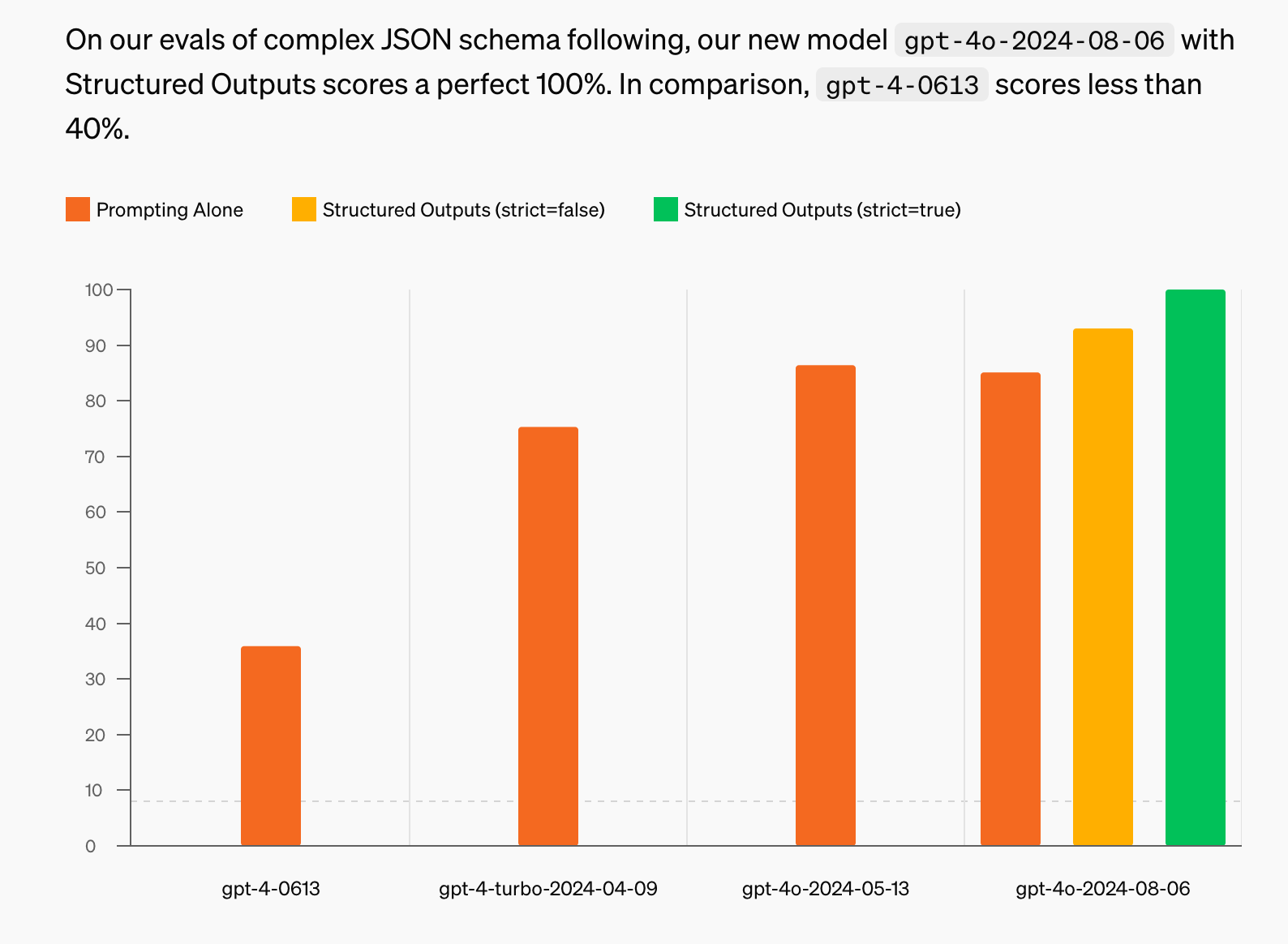
模型:支持 GPT-4o 结构化输出、成本继续下降
通过使用 gpt-4o-2024-08-06 模型,Midscene 已支持结构化输出(structured-output)特性,确保了稳定性增强、成本下降了 40%+。
Midscene 现已支持命中 GPT-4o prompt caching 特性,待公司 GPT 平台跟进部署后,AI 调用成本将继续下降。
测试报告:支持动画回放
现在你可以在测试报告中查看每个步骤的动画回放,快速调试自己的运行脚本
提速:合并执行流程,响应提速 30%
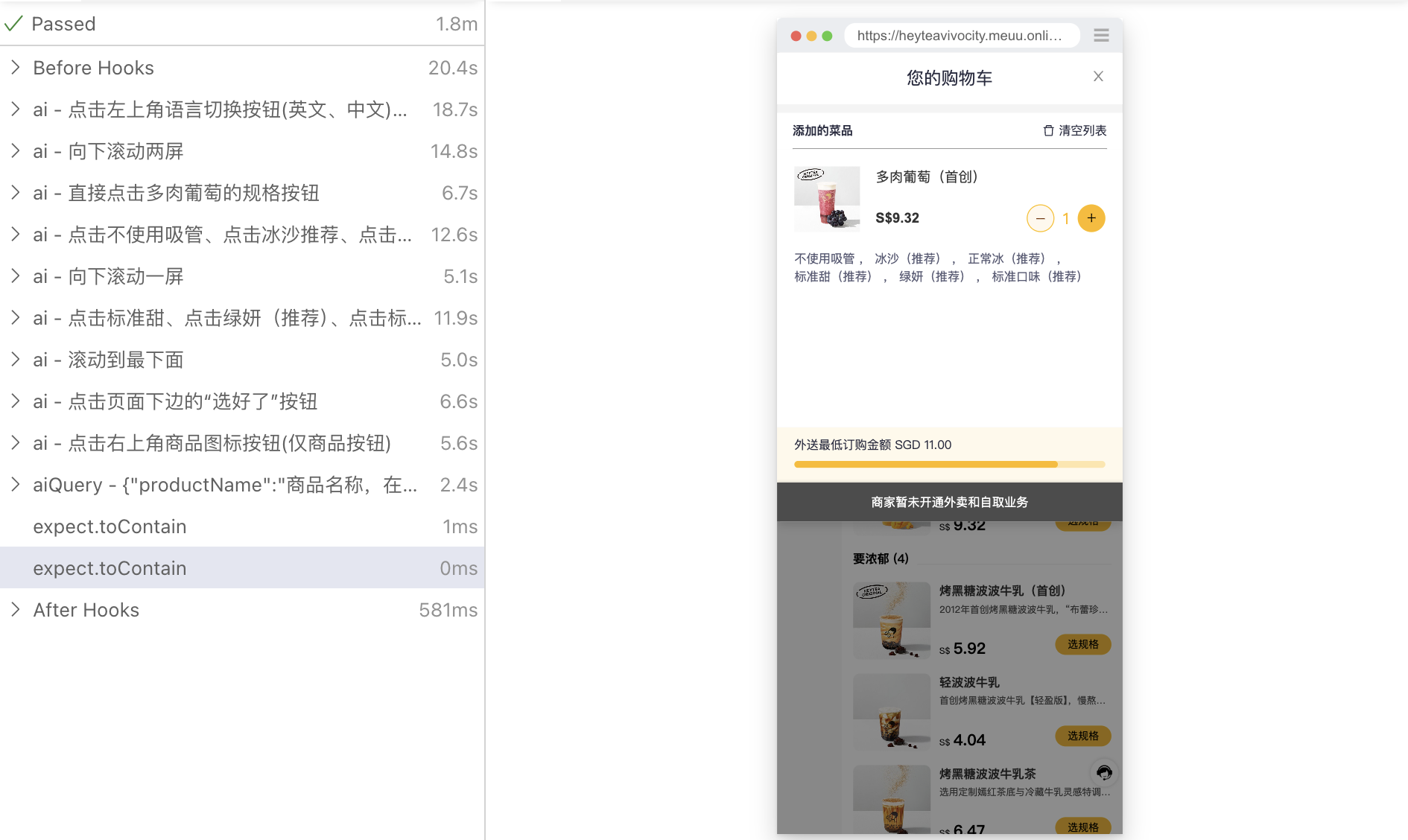
新版本中,我们将 Plan 和 Locate 操作在 prompt 执行上进行一定程度合并,使得 AI 响应速度提升 30%
Before
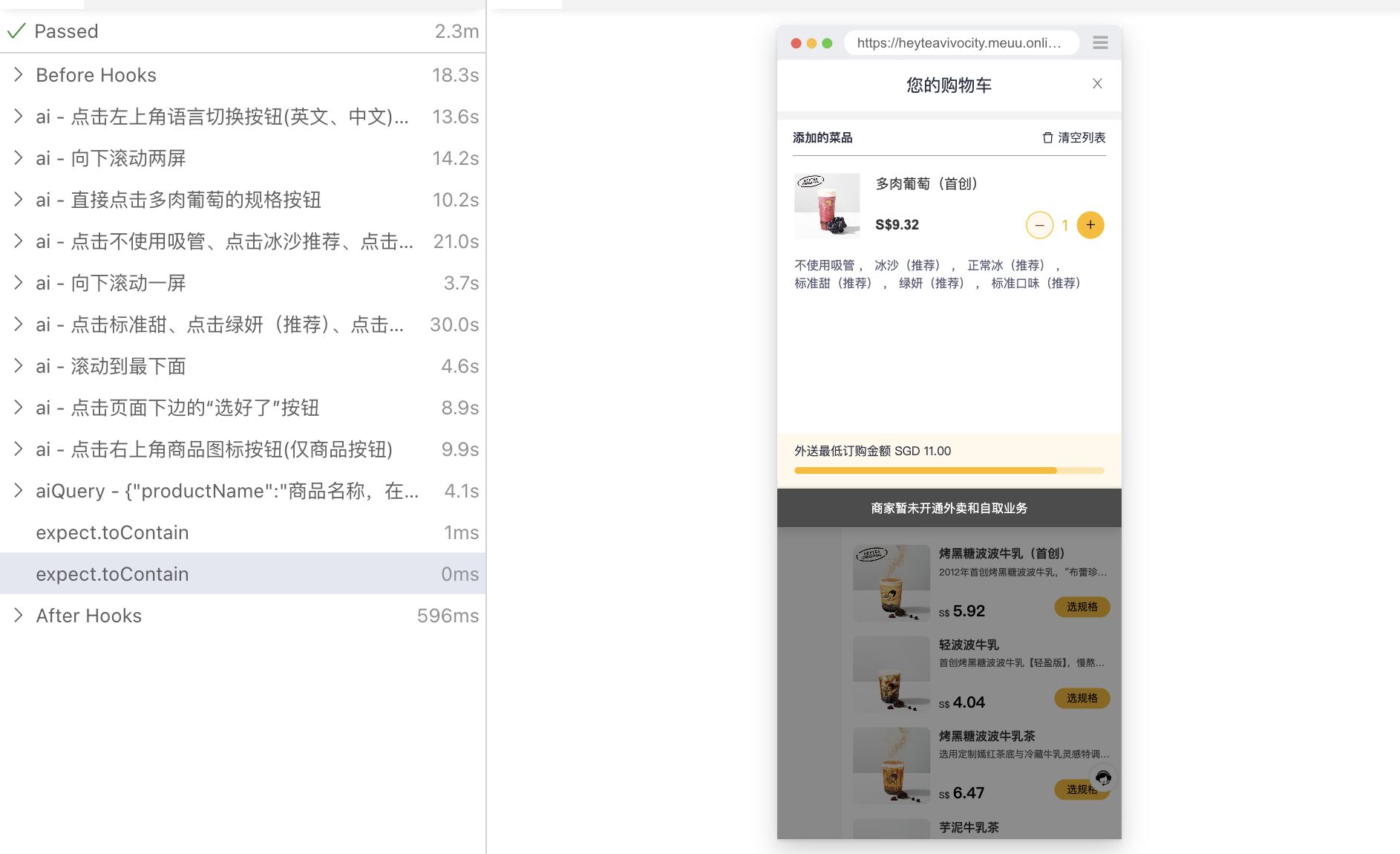
after
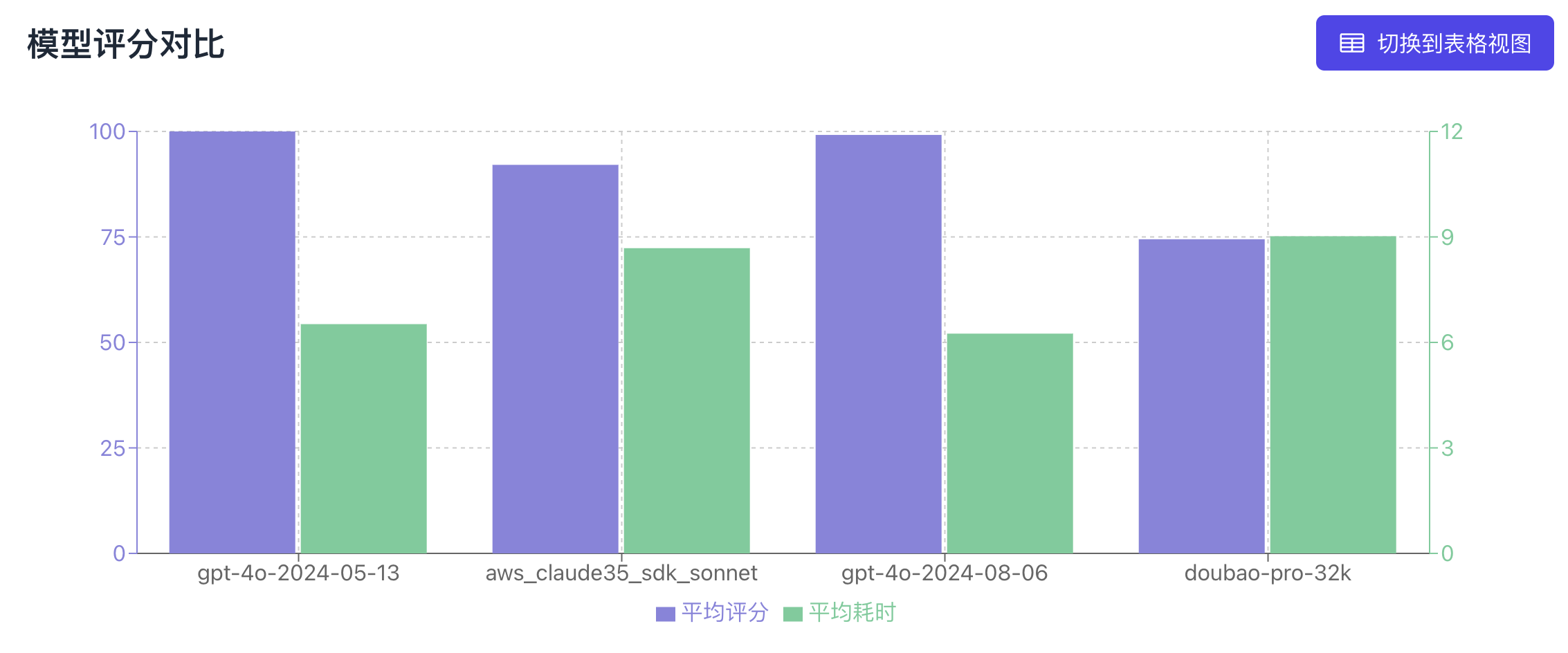
测评报告:不同模型在 Midscene 场景下的表现
-
GPT 4o 系列模型,接近 100% 正确率
-
doubao-pro-4k 纯文本模型,接近可用状态
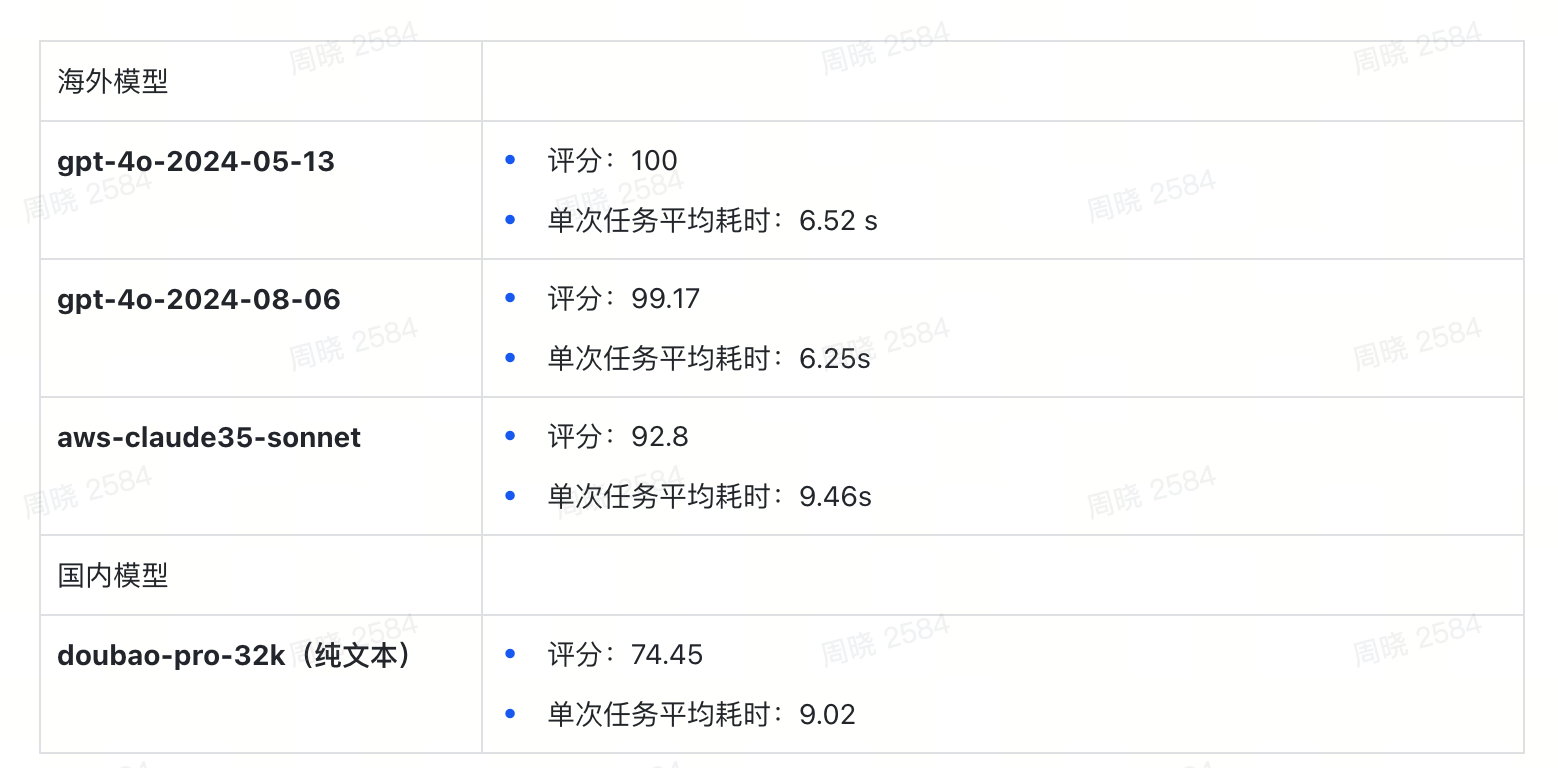
问题修复
优化了页面信息提取,避免遮挡元素被收集,以此优化成功率、速度、AI 调用成本 🚀
before

after

v0.5.0 - 支持 GPT-4o 结构化输出
新功能
- 支持了 gpt-4o-2024-08-06 模型提供 100% JSON 格式限制,降低了 Midscene 任务规划时的幻觉行为
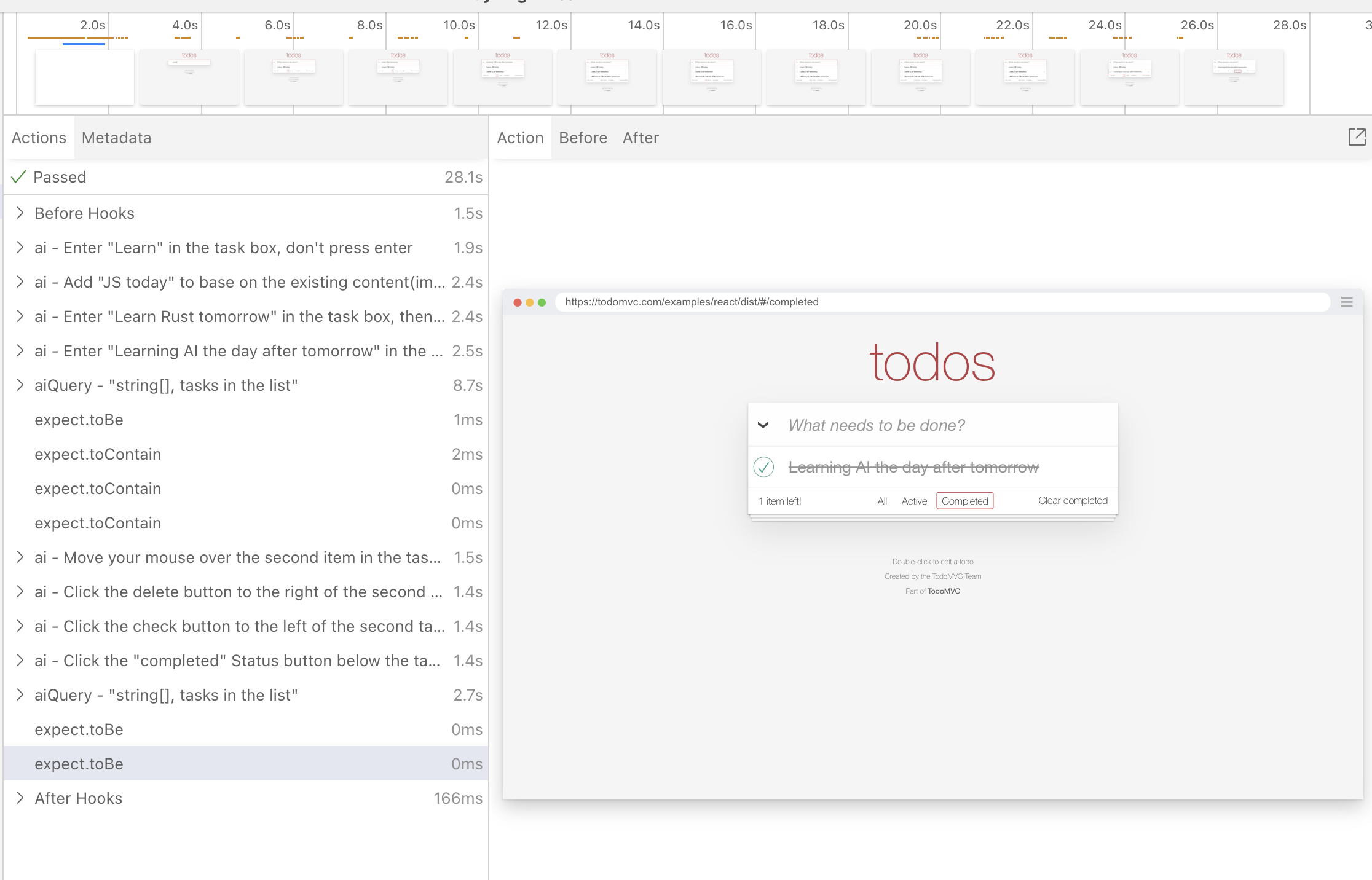
- 支持了 Playwright AI 行为实时可视化,提升排查问题的效率
- 缓存通用化,缓存能力不再仅仅局限于 playwright,pagepass、puppeteer 都可以使用缓存
-
支持了 azure openAI 的调用方式
-
支持了 AI 对于 Input 现有基础之上的增删改行为
问题修复
-
优化了对于非文本、input、图片元素的识别,提升 AI 任务正确性
-
在 AI 交互过程中裁剪了不必要的属性字段,降低了 token 消耗
-
优化了 KeyboardPress、Input 事件在任务规划时容易出现幻觉的情况
-
针对 pagepass 通过 Midscene 执行过程中出现的闪烁行为,提供了优化方案
v0.4.0 - 支持使用 Cli
新功能
- Midscene 支持 Cli 的使用方式,降低 Midscene 使用门槛
-
支持 AI 执行等待能力,让 AI 等到某个时候继续后续任务执行
-
Playwright AI 任务报告展示整体耗时,并按测试组进行聚合 AI 任务
问题修复
- 修复 AI 在连续性任务时容易出现幻觉导致任务规划失败
v0.3.0 - 支持 AI HTML 报告
新功能
- AI 报告 html 化,将测试报告按测试组聚合,方便测试报告分发
问题修复
- 修复 AI 报告滚动预览问题
v0.2.0 - 通过自然语言控制 puppeteer
新功能
-
支持通过自然语言控制 puppeteer 实现页面操作自动化🗣️💻
-
在 playwright 框架中提供 AI 缓存能力,提高稳定性和执行效率
-
AI 报告可视化按照测试组进行合并,优化聚合展示
-
支持 AI 断言能力,让 AI 判断页面是否满足某种条件
v0.1.0 - 通过自然语言控制 playwright
新功能
-
通过自然语言控制 playwright 实现页面操作自动化 🗣️💻
-
通过自然语言提取页面信息 🔍🗂️
-
AI 报告,AI 行为、思考可视化 🛠️👀
-
直接使用 GPT-4o 模型,无需任何训练 🤖🔧