

即时操作和深度思考
从 Midscene v0.14.0 开始,我们引入了两个新功能:即时操作(Instant Actions)和深度思考(Deep Think)。
即时操作(Instant Actions)- 让交互表现更稳定
你可能已经熟悉我们的 .ai 接口。它是一个自动规划接口,用于与网页进行交互。例如,当进行搜索时,你可以这样做:
在接口的背后,Midscene 会调用 LLM 来规划步骤并执行它们。你可以在报告中看到整个过程。这是一个非常常见的 AI Agent 运行模式。
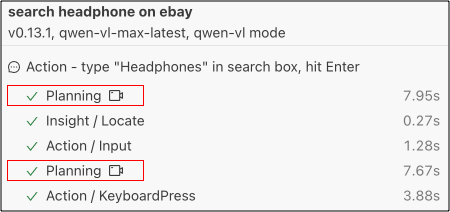
与此同时,许多测试工程师希望有一个更快的方式来执行 UI 操作。当在 AI 模型中使用复杂 prompt 时,一些 LLM 模型可能规划出错误的步骤,或者返回元素的坐标不准确。这些不可预测的过程时常常会让人感受到挫败。
为了解决这个问题,我们引入了 aiTap(), aiHover(), aiInput(), aiKeyboardPress(), aiScroll() 接口。这些接口会直接执行指定的操作,而 AI 模型只负责底层任务,如定位元素等。使用这些接口后,整个过程可以明显更快和更可靠。
例如,上面的搜索操作可以重写为:
在报告中,你会看到现在已经没有了规划 (Planning) 过程:
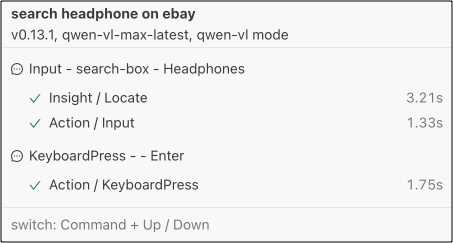
使用这些接口的脚本看起来有点冗余(或者不太“智能”),但请相信,使用这些结构化的接口确实是一个节省时间的好方法,尤其是在操作已经非常明确的时候。
深度思��考(Deep Think)- 让元素定位更准确
当使用 Midscene 与一些复杂的 UI 控件交互时,LLM 可能很难定位目标元素。我们引入了一个新的选项 deepThink(深度思考)到即时操作接口中。
启用 deepThink 的即时操作函数签名如下:
deepThink 是一种策略。它会首先找到一个包含目标元素的区域,然后“聚焦”在这个区域中再次搜索元素。通过这种方式,目标元素的坐标会更准确。
让我们以 Coze.com 的工作流编辑页面为例。这个页面有许多自定义的图标在侧边栏。这对于 LLM 来说很难区分目标元素和它的周围元素。
在即时操作中使用 deepThink 后,脚本会变成这样(当然,你也可以使用 javascript 接口):
通过查看报告文件,你会看到 Midscene 已经找到了页面中的每个目标元素。

就像上面的例子一样,精细的 deepThink 提示词是保持结果稳定的关键。
deepThink 只适用于支持视觉定位的模型,如 qwen2.5-vl。如果你使用的是像 gpt-4o 这样的模型,deepThink 将无法发挥作用。