

Prompting tips
The natural language parameter passed to Midscene will be part of the prompt sent to the AI model. There are certain techniques in prompt engineering that can help improve the understanding of user interfaces.
The goal is to get a stable response from AI
Since AI has the nature of heuristic, the purpose of prompt tuning should be to obtain stable responses from the AI model across runs. In most cases, to expect a consistent response from AI model by using a good prompt is entirely feasible.
Use detailed descriptions and samples
Detailed descriptions and examples are always welcome.
For example:
❌ Don't
✅ Do
❌ Don't
✅ Do
Use instant action interface if you are sure about what you want to do
For example:
agent.ai('Click Login Button') is the auto planning mode, Midscene will plan the steps and then execute them. It will cost more time and tokens.
By using agent.aiTap('Login Button'), you can directly using the locating result from the AI model and perform the click action. It's faster and more accurate compared to the auto planning mode.
For more details, please refer to API.
Understand the reason why .ai is wrong
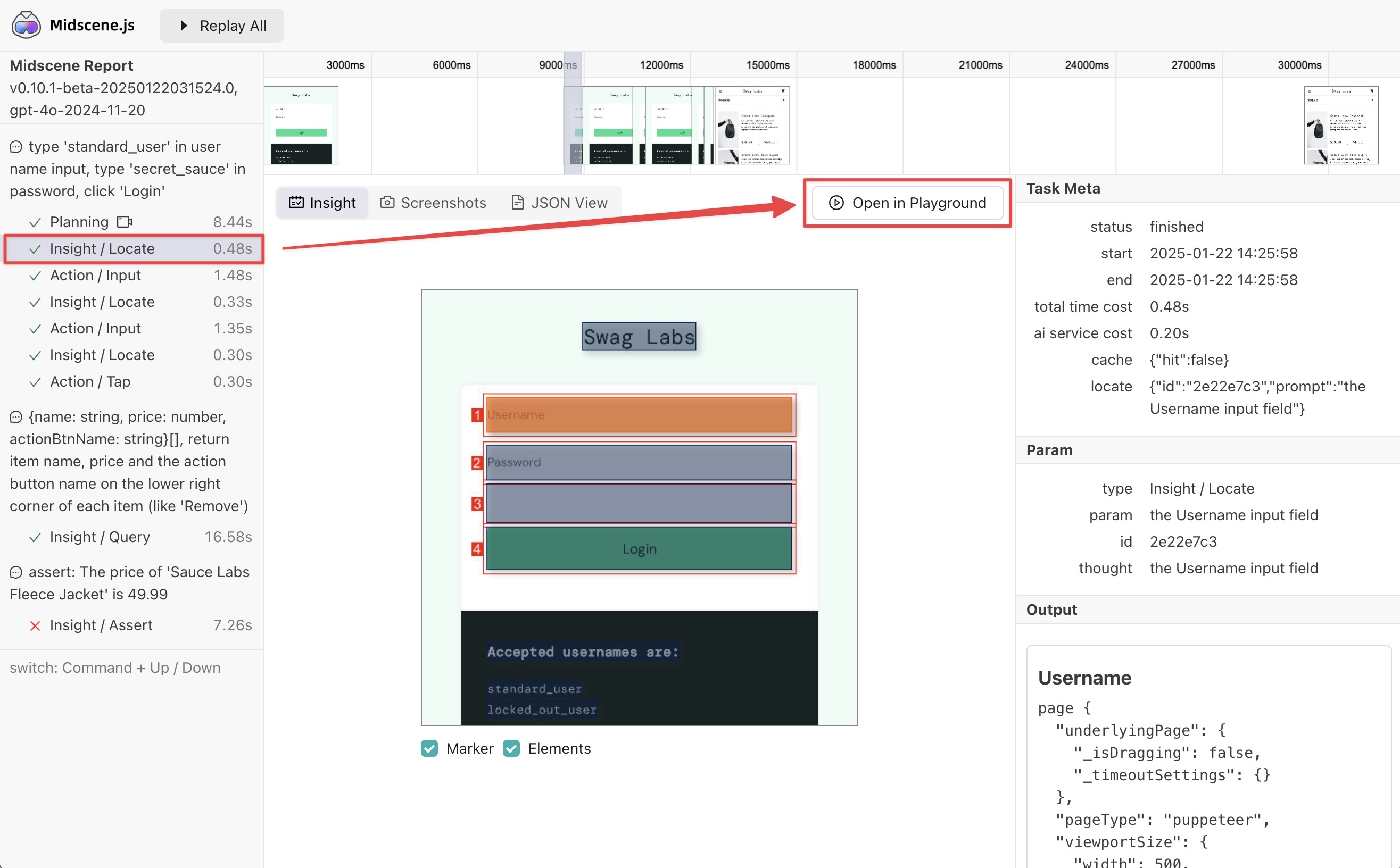
Understanding the report
By reviewing the report, you can see there are two main steps of each .ai call:
- Planning
- Locating
First, you should find out whether the AI is wrong in the planning step or the locating step.
When you see the steps are not as expected (more steps or less steps), it means the AI is wrong in the planning step. So you can try to give more details in the task flow.
For example:
❌ Don't
You can try:
✅ Do
When you see the locating result is not as expected (wrong element or biased coordinates), try to give more details in the locate parameter.
For example:
❌ Don't
You can try:
✅ Do
Other ways to improve
- Use a larger and stronger AI model
- Use instant action interface like
agent.aiTap()instead of.aiif you are sure about what you want to do
One prompt should only do one thing
Use .ai each time to do one task. Although Midscene has an auto-replanning strategy, it's still preferable to keep the prompt concise. Otherwise the LLM output will likely be messy. The token cost between a long prompt and a short prompt is almost the same.
❌ Don't
✅ Split the task into the following steps into multiple .ai calls
LLMs can not tell the exact number like coords or hex-style color, give it some choices
For example:
❌ Don't
❌ Don't
✅ Do
Use report file and playground tool to debug
Open the report file, you will see the detailed information about the steps. If you want to rerun a prompt together with UI context from the report file, just launch a Playground server and click "Send to Playground".
To launch the local Playground server:
Infer or assert from the interface, not the DOM properties or browser status
All the data sent to the LLM is in the form of screenshots and element coordinates. The DOM and the browser instance are almost invisible to the LLM. Therefore, ensure everything you expect is visible on the screen.
❌ Don't
❌ Don't
❌ Don't
✅ Do
Cross-check the result using assertion
LLM could behave incorrectly. A better practice is to check its result after running.
For example, you can check the list content of the to-do app after inserting a record.
Non-English prompting is acceptable
Since most AI models can understand many languages, feel free to write the prompt in any language you prefer. It usually works even if the prompt is in a language different from the page's language.
✅ Good